活用例
 アルコールを分類するE-Nose
アルコールを分類するE-Nose
この事例の目標は、5種類のアルコール(1-オクタノール、1-プロパノール、2-ブタノール、2-プロパノール、1-イソブタノール)を分類するE-Noseモデルを設計することです。 E-nose(electric nose: 電子的な”鼻”、臭覚センサー)とは、人間の感覚能力を模して設計された、生物由来のものも含む化学物質の複雑な混合物を検出するためのセンサーです。
E-noseの構築のために、QCM(Quartz Crystal Microbalance: 水晶振動子マイクロバランス)という装置から得られたデータを使います。 この装置は、付着した気体の質量に応じた、水晶振動子の共振周波数の変化量を出力として返すものです。 この例では、気体の種類ごとの異なる濃度における測定周波数をもとに、E-Noseモデルを構築していきます。
リンク:
 アプリケーションの選択
アプリケーションの選択
予測する変数はカテゴリカル(1-オクタノール、1-プロパノール、2-ブタノール、2-プロパノール、1-イソブタノール)なので、分類モデルとなります。
 データセットの設定
データセットの設定
最初のステップは、分類モデルの情報源であるデータセットの準備です。 データセットは以下で構成されています。
- データソース
- 変数
- インスタンス
この事例のデータは、列数(変数の数)が6個、行数(インスタンスの数)が25個です。 変数は以下のものです。
入力
- 濃度1(空気/ガス比=0.799ml: 0.201ml)における測定周波数[Hz]
- 濃度2(空気/ガス比=0.700ml: 0.300ml)における測定周波数[Hz]
- 濃度3(空気/ガス比=0.600ml: 0.400ml)における測定周波数[Hz]
- 濃度4(空気/ガス比=0.501ml: 0.499ml)における測定周波数[Hz]
- 濃度5(空気/ガス比=0.400ml: 0.600ml)における測定周波数[Hz]
ターゲット
- クラス(1-オクタノール、1-プロパノール、2-ブタノール、2-プロパノール、1-イソブタノール)
初めの5つの入力が、各アルコールが5パターンの異なる濃度でセンサーを通過した際の測定周波数です。 もともとの水晶振動子の共振周波数との差を表すため、負の値をとります。
ニューラルネットワークが扱うのは、あくまで数値だということに注意が必要です。 そのためカテゴリカルな"クラス"変数は、以下のように5つの数値的な変数に変換されます。
- 1-オクタノール: 1 0 0 0 0
- 1-プロパノール: 0 1 0 0 0
- 2-ブタノール: 0 0 1 0 0
- 2-プロパノール: 0 0 0 1 0
- 1-イソブタノール: 0 0 0 0 1
このデータセットを、訓練用、テスト用に分割します。 それぞれがインスタンス全体の60%(15個)、40%(10個)を含むようランダムに分けます。
データセットの設定が済むと、変数の分布を計算できます。
次の図は、各インスタンスをアルコールの種類ごとに分けた円グラフです。
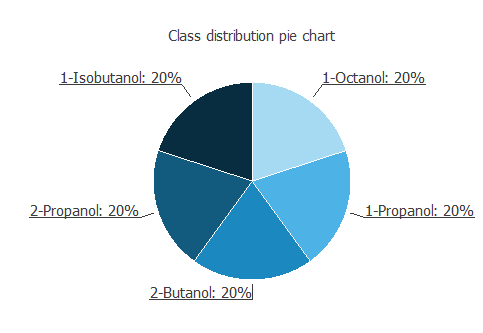 見ての通り、5種類のアルコールが同じ数だけデータに含まれていることが分かります。
見ての通り、5種類のアルコールが同じ数だけデータに含まれていることが分かります。
また、入力とターゲットとの相関を調べることで、どの入力が最も予測に影響を与えるかの示唆を得られることがあります。
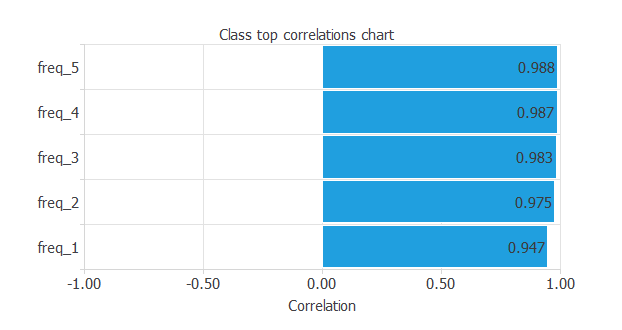 この例では、どの入力もターゲットであるクラスと強く相関していることが上の図から分かります。
この例では、どの入力もターゲットであるクラスと強く相関していることが上の図から分かります。
 ネットワーク構造の設定
ネットワーク構造の設定
次のステップは、ニューラルネットワークの設定です。 分類タイプのモデルは通常、
- スケーリング層
- パーセプトロン層
- 確率層
スケーリング層
スケーリング層は、入力の統計情報とスケーリング手法を含みます。 ここでは最小値と最大値のスケーリング手法を採用しますが、平均値と標準偏差のスケーリング手法を用いても非常に似た結果を出します。パーセプトロン層
この事例では、パーセプトロン層は用いません。 これは学習するデータが小さいためで、これにより課題を簡略化しています。
確率層
確率層では、出力を確率として解釈できるようにします。 つまり、全ての出力が0から1の値をとり、その総和が1となるようにします。 この事例では、ソフトマックス関数を用いて変換します。 ターゲットが5つのクラス(1-オクタノール、1-プロパノール、2-ブタノール、2-プロパノール、1-イソブタノール)を持つため、同じく5つの出力を持ちます。
 学習手法の設定
学習手法の設定
次は学習手法の設定です。以下の2つの要素を設定します。
- 損失関数
- 最適化アルゴリズム
損失関数
損失関数は時差項と正則化項からなり、ターゲットの値と出力値の差を規定します。 この例では、誤差項に正規化二乗誤差、正則化項にL2正則化を選びます。
最適化アルゴリズム
最適化アルゴリズムは、損失関数を最小化するパラメータの探索を担います。 ここでは準ニュートン法を選択します。
以下の図は、学習過程中のエポック数(学習の繰り返し回数)の増加とともに訓練誤差がどのように減少していくかを示しています。
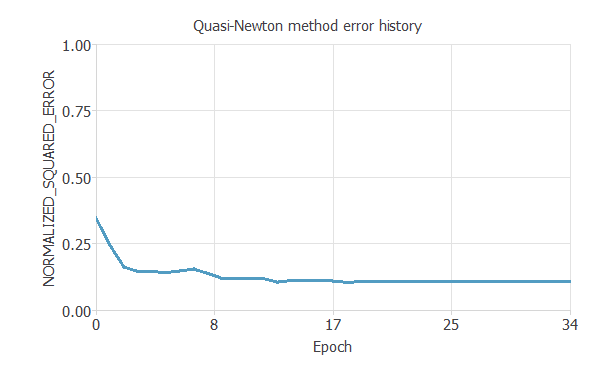 この例では、最終的な訓練誤差は0.109NSEです。
この例では、最終的な訓練誤差は0.109NSEです。
インスタンスを訓練用とテスト用にのみ分けたため、検証誤差はありません。
 モデル選択
モデル選択
モデル選択の目的は、最良の汎化性能を持つネットワークアーキテクチャを見つけること、つまり、検証誤差を最小化することです。
この例では、検証用インスタンスは用意していないため、モデル選択は行いません。
その他の事例で用いるニューロン数選択アルゴリズムでは、ニューロンの数を変えながらネットワークアーキテクチャに学習させ、検証誤差が最小のものを選択します。 例えば、その一種であるグローイングニューロン法では、少ない数のニューロンから始めて反復を繰り返すごとにネットワークの複雑性を増していきます。
 テスト分析
テスト分析
テスト分析の目的は、モデルの汎化性能を評価することです。 ここでは、ニューラルネットワークの出力値とテスト用インスタンス中のターゲットの値を比較します。
出力値と実際の値の比較には、混同行列が有用です。
混同行列では、各行がテスト用インスタンスのターゲットの値(実際の値)を表し、各列がニューラルネットワークの出力値(予測値)を表します。
対角成分が正しく分類されたケース、非対角成分が誤って分類されたケースを示します。
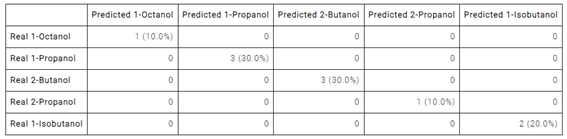 見ての通りこの例では、正しく予想されたインスタンスの数が10個(100%)で、誤分類はありません。
これはモデルが優れた分類精度を持っていることを示しています。
見ての通りこの例では、正しく予想されたインスタンスの数が10個(100%)で、誤分類はありません。
これはモデルが優れた分類精度を持っていることを示しています。
 モデルの利用
モデルの利用
ここまでのステップで、見たことのない入力値に対してターゲットを予測する準備が整いました。
異なる濃度における測定周波数を入力として、その気体が各種のアルコールである確率を出力します。 例えば、以下の入力値
- 濃度1における測定周波数: -54.764[Hz]
- 濃度2における測定周波数: -90.826[Hz]
- 濃度3における測定周波数: -132.372[Hz]
- 濃度4における測定周波数: -173.337[Hz]
- 濃度5における測定周波数: -220.833[Hz]
- 1-オクタノールの確率: 1.5%
- 1-プロパノールの確率: 9.6%
- 2-ブタノールの確率: 1.3%
- 2-プロパノールの確率: 24.2%
- 1-イソブタノールの確率: 63.4%