活用例
 複合火力発電所の排気量の削減
複合火力発電所の排気量の削減

複合火力発電所(コンバインドサイクル発電所)は、ガスタービン、蒸気タービン、排熱回収型蒸気発生器で構成されています。 このタイプの発電所では、ガスタービンと蒸気タービンを組み合わせた1つのサイクルで発電し、タービンから別のタービンに電気を送ります。 このプロセスでは、NOx(窒素酸化物)などの健康に有害なガスが排出されます。 このような排出量のピークを予測することができれば、予防策を講じることができるかもしれません。
この例では、NOx排出量をモデル化することで、排出量とその削減方法に関する重要な情報を得ることを目的としています。
リンク:
 アプリケーションの選択
アプリケーションの選択
予測すべき変数(NOx排出量)が連続的であるため、近似モデルです。
ここでの目標は、環境変数と装置の制御変数の関数としてNOx排出量をモデル化することです。
 データセットの設定
データセットの設定
データセットは次の3つのコンセプトで構成されています。
- データソース
- 変数
- インスタンス
この例のデータセットには、2011年から2015年の間にトルコ北西部に設置されたガスタービンで1時間ごとに集計された、11変数の36733サンプルが含まれています。 変数は以下の通りです。
入力
- 環境温度[℃]
- 環境圧力[mb]
- 環境湿度[%]
- エアフィルタの差圧[mb]
- ガスタービンの排気圧力[mb]
- タービンユニットに流入するガスの温度[℃]
- タービンユニットから排出されるガスの温度[℃]
- コンプレッサーから排出されるガスの圧力[mb]
- タービンの1時間あたりの総発電量[MW/h]
ターゲット
- NOx(窒素酸化物)の濃度[mg/m3]
このデータセットを、訓練用、検証用、テスト用のサブセットに分けます。 各サブセットが、インスタンス全体の60%、20%、20%を含むようランダムに分割します。
データの分布を計算することで、データの正しさを確認したり、異常を検出したりできます。
次の図は、NOxの分布を示すヒストグラムです。
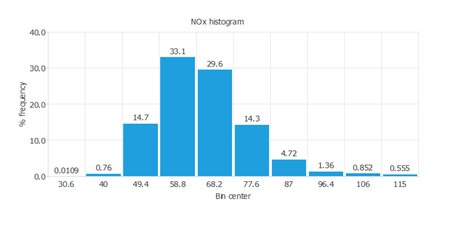 NOxは正規分布に従っていることが分かります。
NOxは正規分布に従っていることが分かります。
また、1つの入力と1つのターゲットの間の相関関係を調べることも重要です。
そのために、入力とターゲットの相関図をプロットすることができます。
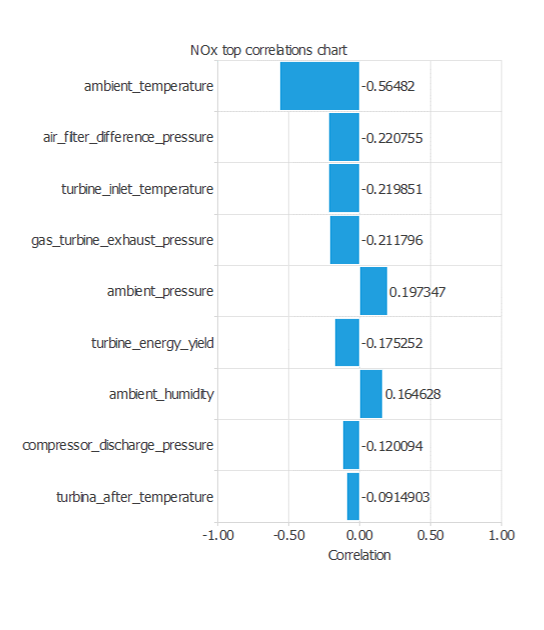 この場合、NOx排出量との相関が最も強いのは"ambient_temperture: 環境温度"です(温度が高いほどNOxの排出量は少なくなります)。
この場合、NOx排出量との相関が最も強いのは"ambient_temperture: 環境温度"です(温度が高いほどNOxの排出量は少なくなります)。
次に、ターゲットであるNOx排出量と、最も有意な相関関係にある環境温度の散布図をプロットしてみます。
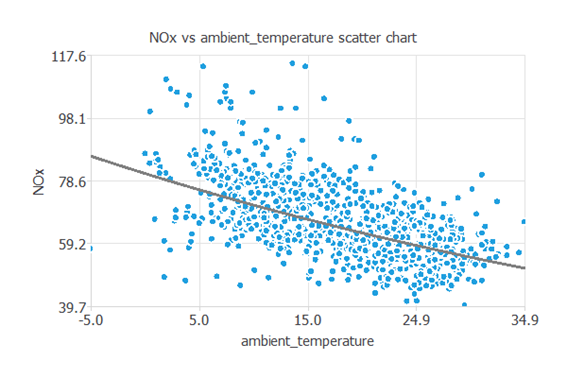 環境温度が高いほど発電所から排出されるガスの量は少なくなることがわかります。
環境温度が高いほど発電所から排出されるガスの量は少なくなることがわかります。
 ネットワーク構造の設定
ネットワーク構造の設定
このステップでは、近似関数を表すニューラルネットワークを構築します。 近似モデルの場合、通常は次のように構成します。
- スケーリング層
- パーセプトロン層
- アンスケーリング層
スケーリング層
スケーリング層には、入力の統計情報が含まれています。 この例では、データに最適なスケーリング手法を適用するため、自動設定を使用しています。
パーセプトロン層
ここでは2つのパーセプトロン層を使用しています。 1つめのパーセプトロン層は、9つの入力、3つのニューロン、活性化関数として双曲線正接関数を持っています。 2つめのパーセプトロン層は、3つの入力、2つのニューロン、活性化関数として線形関数を持ちます。
アンスケーリング層
アンスケーリング層には、ターゲットの統計情報が含まれています。 スケーリング層と同様に自動化された方法を用います。
次の図は、この例のニューラルネットワークを表しています。
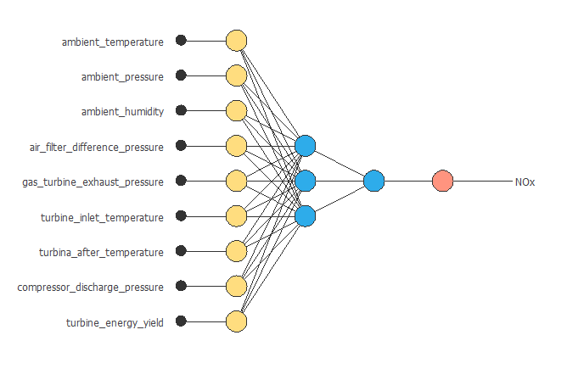
 学習手法の設定
学習手法の設定
ここでは、適切な学習手法を選択します。 一般的な学習手法は、2つのコンセプトで構成されています。
- 損失関数
- 最適化アルゴリズム
損失関数
損失関数は、ニューラルネットワークが学習する量を定義し、誤差項と正則化項で構成されています。
誤差項としては、正規化二乗誤差を選択しました。 これは、ニューラルネットワークからの出力値とデータセット内のターゲットの値との間の二乗誤差を、その正規化係数で割ったものです。 正規化二乗誤差の値が1であれば、ニューラルネットワークはデータを"平均的に"予測していることを意味し、0であればデータを完全に予測していることを意味します。 この誤差項には、設定するパラメータはありません。
正則化項は、L2正則化です。 これは、パラメータの値を減らすことで、ニューラルネットワークの複雑さを制御するために適用されます。 この正則化項には弱い重みを使用しています。
最適化アルゴリズム
最適化アルゴリズムは、損失指数を最小化するようなニューラルネットワークのパラメータの探索を担います。 ここでは、準ニュートン法を最適化アルゴリズムとして採用しました。
下の図は、訓練データ(青)と検証データ(オレンジ)の誤差が、学習中のエポック(繰り返し回数)に応じて減少する様子を示しています。
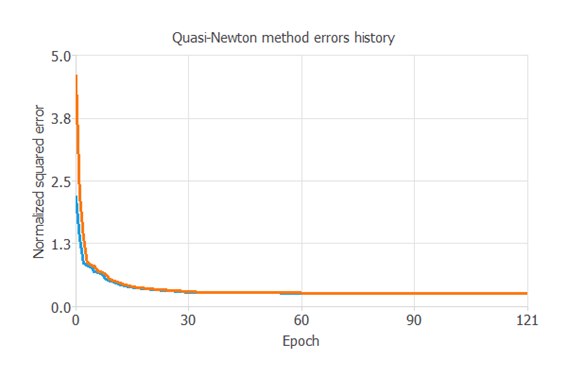 最終的な値はそれぞれ、訓練誤差=0.260NSE、検証誤差=0.263NSEとなります。
最終的な値はそれぞれ、訓練誤差=0.260NSE、検証誤差=0.263NSEとなります。
 モデル選択
モデル選択
モデル選択の目的は、最良の汎化性能を持つネットワーク構造を見つけることです。 つまり、上で得られた最終的な検証誤差(0.263NSE)を改善することを目的とします。
最適な検証誤差は、入力とターゲットの関係を表すのに最も適した複雑さを持つモデルを使用することで達成されます。 そのために用いるニューロン数選択アルゴリズムは、ニューラルネットワーク内のパーセプトロンの最適なニューロン数を見つける役割を担います。
次のグラフは、ニューロン数選択アルゴリズムの結果を示しています。
青い線は、最終的な訓練誤差をニューロン数の関数としてプロットしています。
オレンジ色の線は、最終的な検証誤差をニューロン数の関数としてプロットしています。
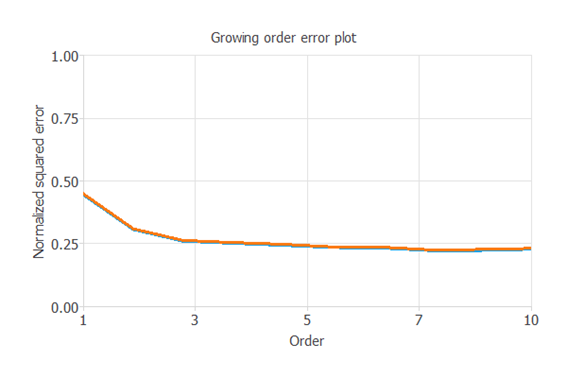 このように、最終的な学習誤差は、ニューロンの数が増えれば増えるほど常に減少します。
しかし、最終的な検証誤差はある時点で最小値をとります。
この例では最適なニューロンの数は8であり、このときの検証誤差は0.224NSEです。
このように、最終的な学習誤差は、ニューロンの数が増えれば増えるほど常に減少します。
しかし、最終的な検証誤差はある時点で最小値をとります。
この例では最適なニューロンの数は8であり、このときの検証誤差は0.224NSEです。
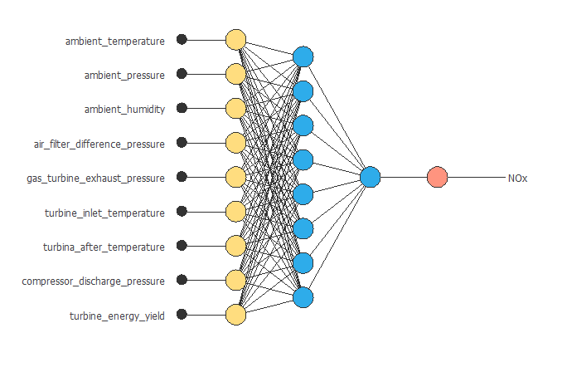
次の図は、この例の最適化されたネットワーク構造を示しています。
 テスト分析
テスト分析
テスト分析の目的は、ニューラルネットワークの汎化性能を検証することです。 データセットの中で、これまで使っていないテスト用のインスタンスを使用します。
近似モデルにおける標準的なテスト方法は、予測されたNOxの値と実際のNOxの値の間で線形回帰分析を行うことです。
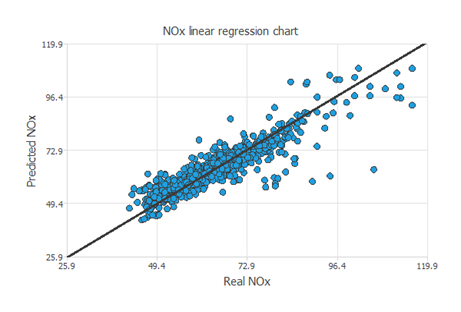 完全に近似できている場合、相関係数R2は1となります。
R2=0.889なので、ニューラルネットワークはテストデータをよく予測していることになります。
完全に近似できている場合、相関係数R2は1となります。
R2=0.889なので、ニューラルネットワークはテストデータをよく予測していることになります。
 モデルの利用
モデルの利用
ニューラルネットワークを、見たことのない入力値に対してターゲットを予測するために使用します。 例えば、以下の入力値
- 環境温度: 17.713[℃]
- 環境圧力: 1013.07[mb]
- 環境湿度: 77.867[%]
- エアフィルタの差圧: 3.926[mb]
- ガスタービンの排気圧力: 25.56[mb]
- タービンユニットに流入するガスの温度: 1081.44[℃]
- タービンユニットから排出されるガスの温度: 546.161[℃]
- コンプレッサーから排出されるガスの圧力: 133.506[mb]
- タービンの1時間あたりの総発電量: 12.061[MW/h]
- NOx(窒素酸化物)の濃度: 67.518[mg/m3]
また、ニューラルネットワークのDirectional outputをプロットすることで、他のすべての入力値が固定されている場合に、ある入力値の変化に対して出力値がどのように変化するかを見ることができます。
ここでは例として、タービンユニットから排出されるガスの温度が、NOx排出量にどのような影響を与えるかを見てみます。
それ以外の入力値を上の値に固定した場合のプロットが下の図です。
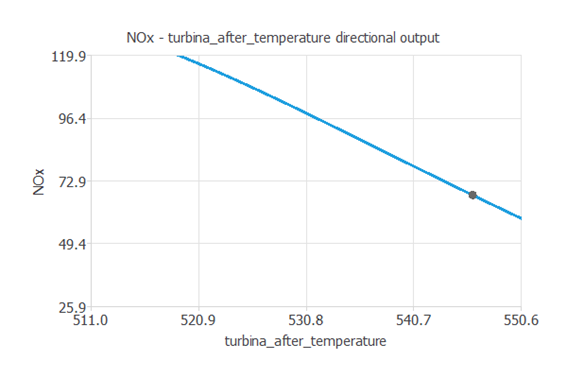 タービンユニットから排出されるガスの温度を下げることで、NOxの排出量が減少することが分かります。
タービンユニットから排出されるガスの温度を下げることで、NOxの排出量が減少することが分かります。
このようにモデルを見極めることで、NOxの排出量を削減する措置を取ることができます。 例えば上の出力を解析すると、タービンユニットから排出されるガスの温度を10℃下げるだけで、NOxのレベルが1立方メートルあたり64.759ミリグラムから54.388ミリグラムへと19.45%減少することがわかります。
ここでは、NOxの低減方法を見るためにタービンユニットから排出されるガスの温度を使用していますが、Directional outputを使用すれば、どのような変数でもこのように分析することができます。