概要
はじめに

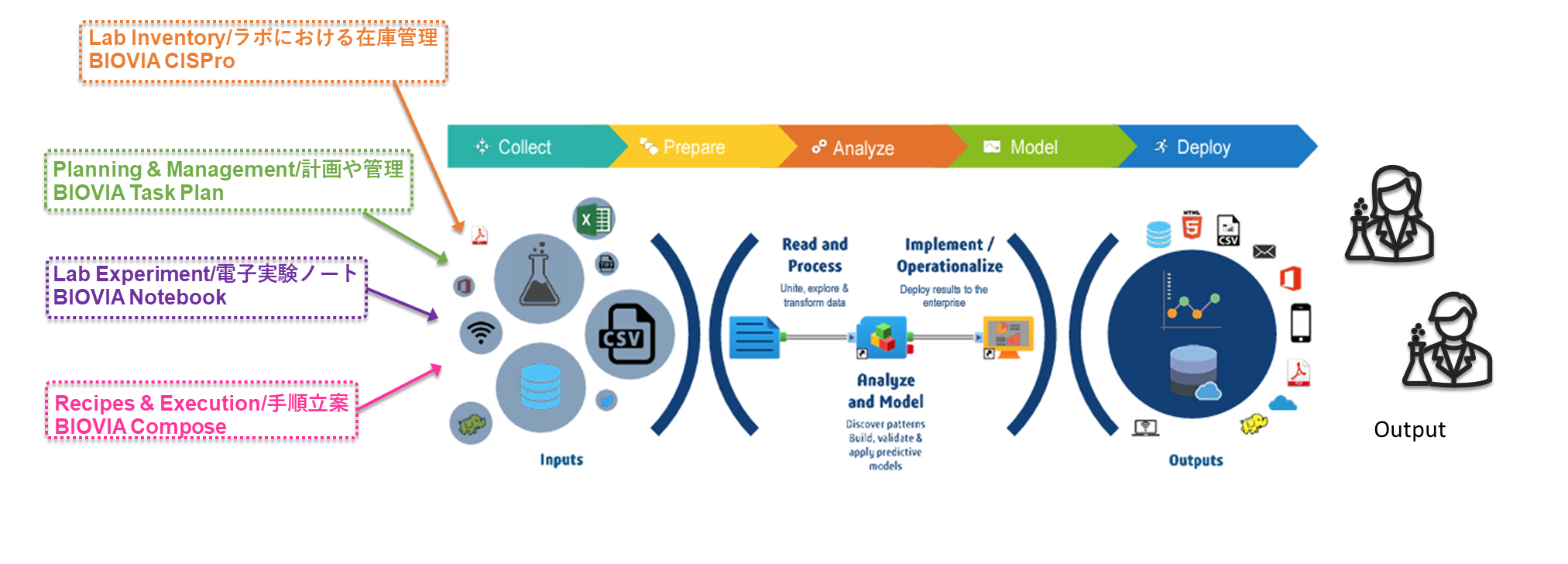
図1. コーティング分野における機械学習活用の全体イメージ

図2. 実験データを整理し、学習用データへ変換するイメージ
今回はコーティング材料やそれら関連材料を取り扱う企業様にご協力いただき、機械学習に注目したベンチマークシミュレーションを行いました。
本件で使用したソフトウェアは BIOVIA Pipeline Pilot です。近年普及が進むAIや機械学習の取り扱いに適しており、ノンコーディングでも利用できる点が特徴です。
今回の検証では、単純にモデルを作成するだけではなく、手元の実験データをどのように前処理し、説明変数テーブルと目的変数テーブルを整形し、再利用可能なワークフローとして定着させるか までを含めて整理しています。実務上はこの前処理設計が工数の多くを占めるため、ここをプロトコル化できるかどうかが運用性に直結します。
特に塗料・コーティング分野では、原料配合、添加剤量、製造条件、評価条件など多種類の因子が一つの特性値に影響します。そのため、Excel 上で管理されている実験履歴をそのまま学習器へ渡すのではなく、特徴量定義・欠損処理・不要列除去・表記統一 を明示した上で学習へ接続することが重要です。
背景
本ベンチマークの背景と目的について

図3. 実験データ整理と解析基盤のイメージ
従来から現代にかけて、より良い特性値をもつ材料を開発することは重要な業務であり、同時に重要な課題でもあります。また、材料の特性値は素材、反応時間、温度、ヒステリシスなど多くの要因に左右されるため、材料開発の効率化も強く求められています。
理想的には、あらゆる条件に対して実験計画法を導入し、実験と測定を重ねた上で最適条件を発見するべきですが、コスト面や時間面から現実的ではありません。
そこで、いくつかの実験条件(説明変数)と特性値(目的変数)を記した少量のデータセットを使用して機械学習を行い、特性値を予測することで最適な実験条件の傾向を掴むことを目的としてベンチマークを実施しました。
本件では、既存データの全件活用よりも、まずは学習に利用可能な列と利用困難な列を切り分け、モデル化可能な最小構成のデータセットを短時間で組み立てられるか を重視しています。これは現場導入時に、完璧なデータ整備を待たずに PoC を立ち上げられるかどうかに直結します。
特に材料開発では、測定結果そのものだけでなく、配合条件や製造条件、評価条件など複数種類の情報を横断して扱う必要があります。そのため、分析担当者だけが理解できる単発のスクリプトではなく、誰が見ても追従できるワークフローとして表現されていることが重要です。
要点
今回のベンチマークで重視したポイント
|
モデル精度だけでなく、実務に載せやすい形で運用できるかを重視しています。
|
手法
ワークフローその1
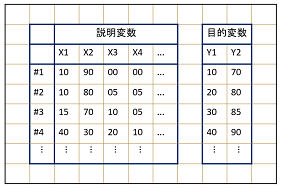
図4. 学習対象データセットの構成イメージ
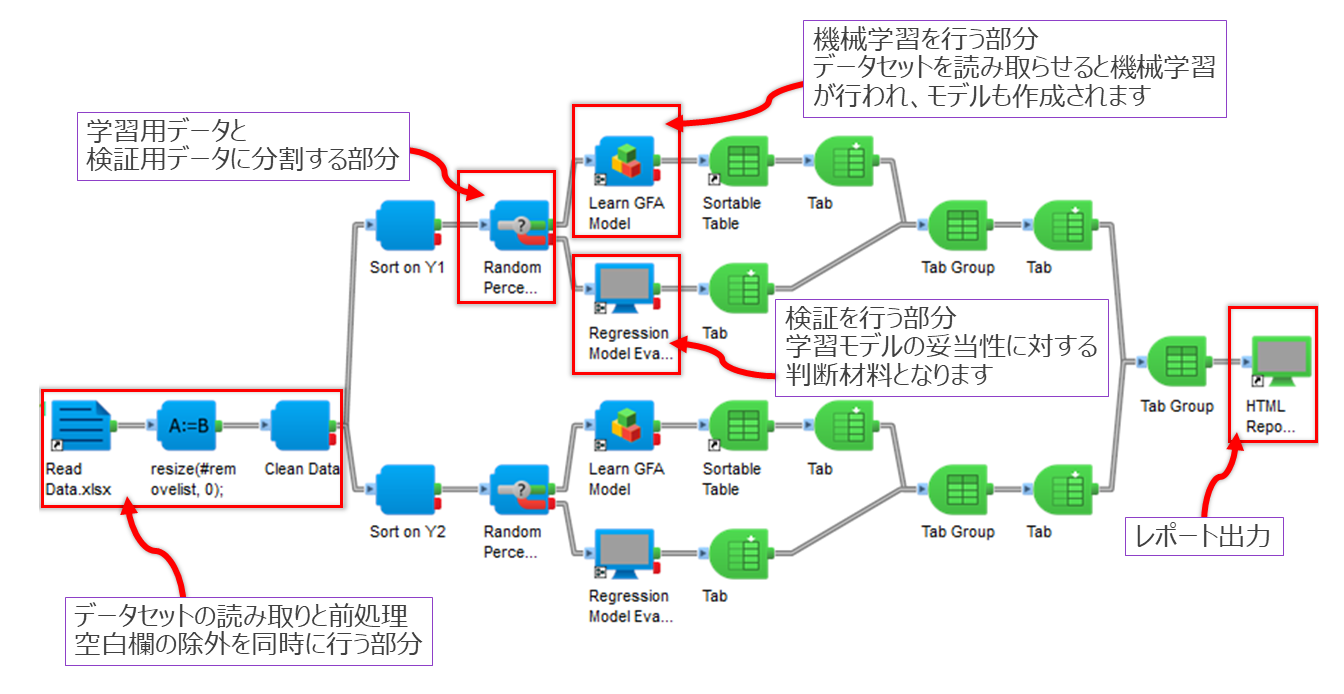
図5. Pipeline Pilot 上に構築した前処理・学習ワークフロー
フローでは、初めに機械学習を行うためのデータ前処理を行い、その後に機械学習を実行しました。学習対象のデータセットはテーブル形式で記述され、各セルに色が割り振られた、表計算ソフト由来のファイルでした。
このようなデータでは、説明変数と目的変数のテーブル分離、日本語表記、# によるナンバリング、空白行、セル色の扱いなどが課題になります。従来の機械学習では、こうした前処理をコーディングで個別に実装する必要がありました。
本ワークフローでは、まず Excel 由来データから学習に不要な装飾情報を除去し、その後に列名統一、カテゴリ値の整理、説明変数テーブル化、目的変数抽出を行っています。さらに、モデル評価のために学習用データと検証用データを分離した上で予測誤差を定量確認できる構成 としました。
Pipeline Pilot では、これらの前処理をワークフローに組み込むことができます。そのため、データを読み取り、機械学習を行い、検証し、レポート出力するまでを一つの流れとして効率的かつ簡潔に実現できました。
ワークフローその1によって作成された機械学習モデルは、検証結果からまだ改善の余地があると判断できるものでした。そのため、精度改善に向けた提案を行い、その比較結果を次項で整理しました。
ここで重要なのは、前処理や学習条件がコンポーネントとして可視化されているため、どこを変更したか・なぜ結果が変わったかを追いやすいことです。これは単に一度予測できるという話ではなく、継続的に改善できる運用基盤を作れることを意味します。
結果
ワークフローその2と結論、今後の活用先
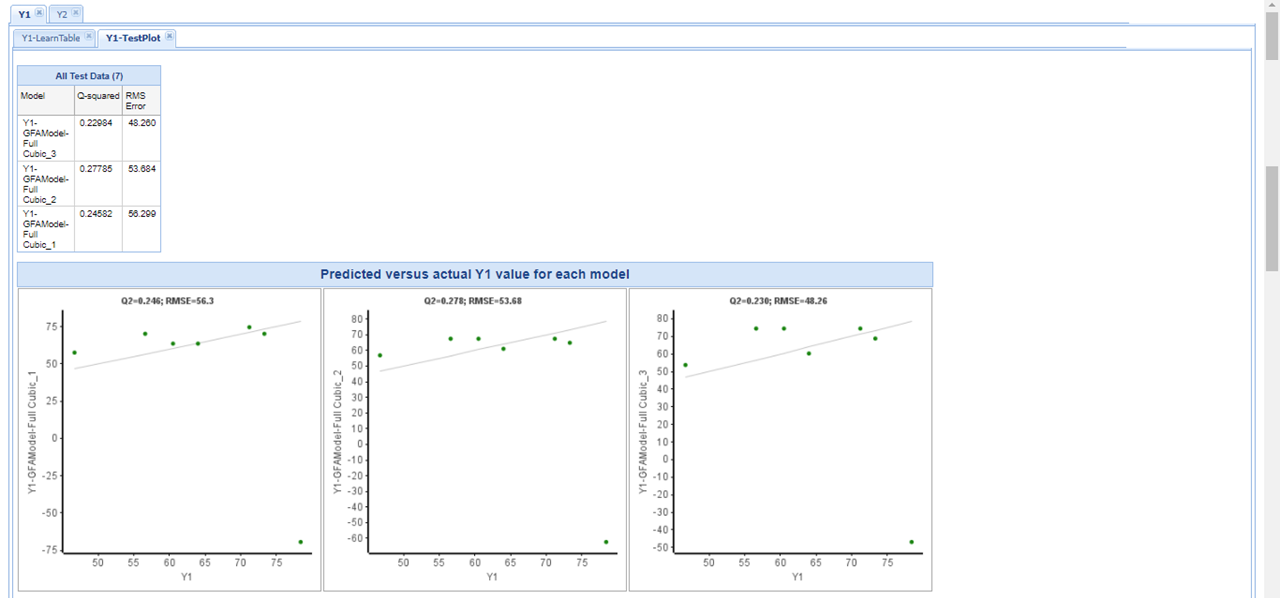
図6. 改善前モデルにおける予測値と実測値の比較
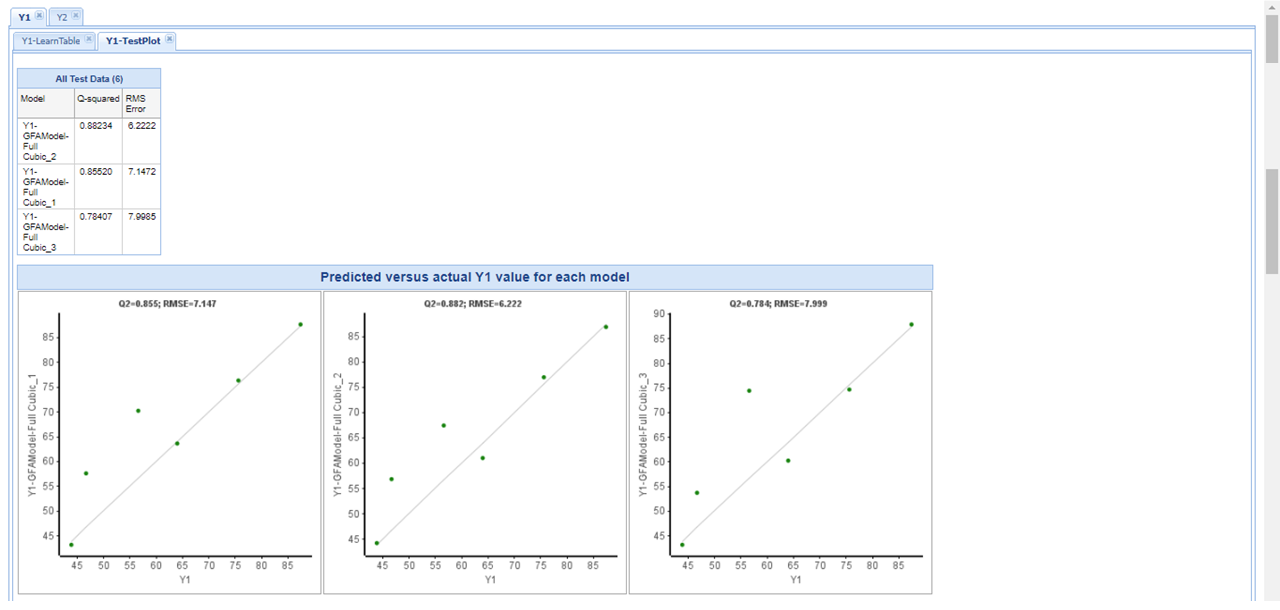
図7. 改善後モデルにおける予測値と実測値の比較
ワークフローその1の結果を踏まえ、精度改善前と改善後の検証結果を比較しました。Pipeline Pilot では作成したワークフローの保存や配布が可能であるため、機械学習条件とワークフローを維持したまま改善検証を進めることができます。
比較の結果、改善後は大きな外れ値を減らし、実測値と予測値の傾向をほぼ同じに揃えられることが確認できました。散布図上でも改善前に比べて相関のばらつきが抑えられており、検証データに対しても過度な崩れが見られないことから、モデル条件の見直しが有効であったと判断できます。
今回のベンチマークでは、Pipeline Pilot の強みの一つである簡単に機械学習を行えることを活かし、機械学習モデルの作成から予測精度の改善までを実現できました。
また、作成された学習モデルの活用先としては、特性値を予測することで最適な実験条件の傾向を掴むことが最も有効であると整理できました。
これは実験そのものを完全に代替するという意味ではなく、候補条件の絞り込みや優先順位付けを支援する位置づけです。探索範囲の広い材料開発では、こうした事前予測が試作回数や評価工数の削減に寄与します。
展開
想定される活用シーン
|
今回の構成は、塗料分野に限らず、説明変数と評価値を持つ材料開発テーマへ展開できます。
|
お問い合わせはこちらから
まずはお気軽にご相談ください。
045-682-7070