
 はじめに
はじめに
|
今回はコーティング材料やそれら関連材料を取り扱っていらっしゃる企業様、
A株式会社様(匿名)にご利用いただきました。 本件においてご利用いただくことのできたソフトウェアは BIOVIA Pipeline Pilotです。 このソフトウェアは、近年において高速に普及しているAIや機械学習の取り扱いに特化しており、 さらにノンコーディングで使用することも可能という特徴がございます。 そのソフトウェアを使用して、本件では機械学習に注目したベンチマークシミュレーションを行いました。 |
 |
本ベンチマークの背景と目的について
|
従来から現代にかけて、どの分野に関わらずより良い特性値をもつ材料を開発することは重要な業務であり、かつ重要な課題でもあります。 また、材料の特性値は様々な要因によって左右されてしまうため材料開発の効率化も求められています。 例えば、材料開発時に使用された素材や反応時間、そして温度、ヒステリシスのような要因によっても左右されるかもしれません。 この条件全てに対して実験計画法を導入し、実際に実験、測定をしたうえで最適な条件を発見することは理想ですが、 それはコスト面や時間的観点から現実的ではありません。 そこで、 いくつかの実験条件(例えば、説明変数X1、X2、X3、X4、、、)と それぞれの特性値(例えば、目的変数Y1、Y2)を記した少量のデータセットを使用して機械学習を行い、 特性値を予測することで最適な実験条件の傾向を掴むことを目的としてベンチマークを行いました。 |
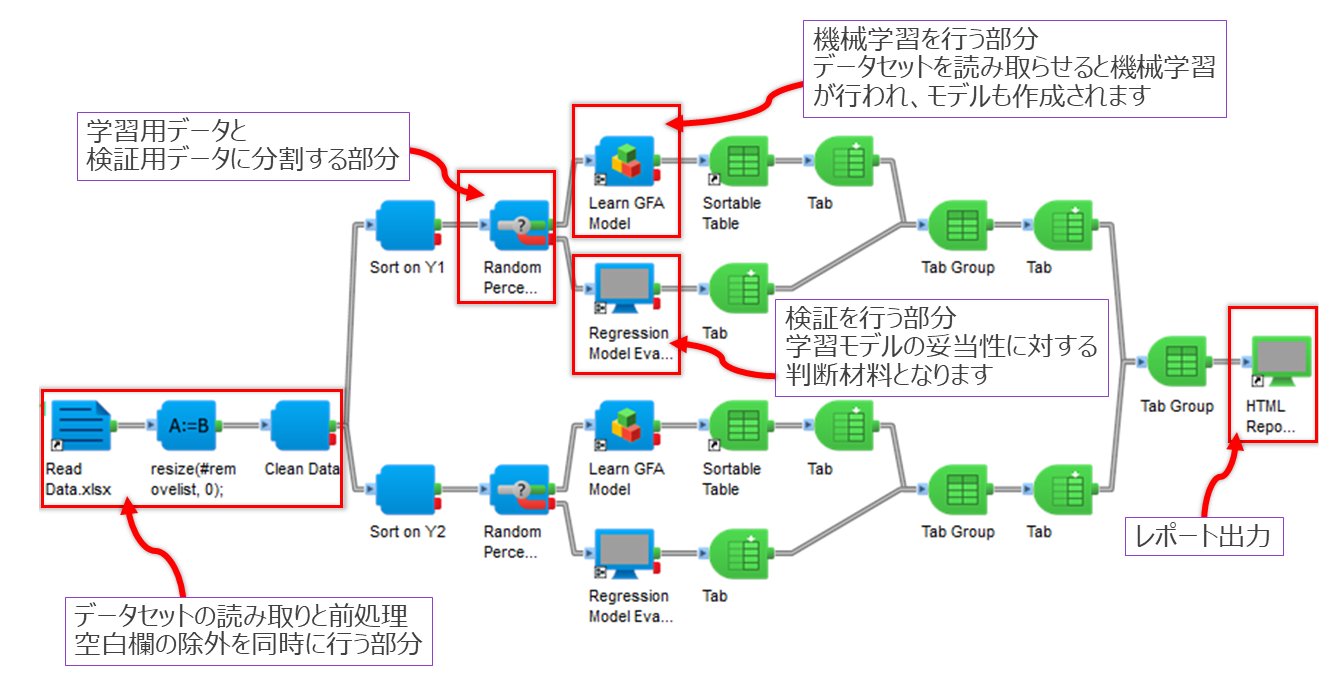
ワークフローその1
|
|
|
|
フローでは、初めに機械学習を行うにあたってのデータ前処理を行い、次にそれを機械学習にかけました。
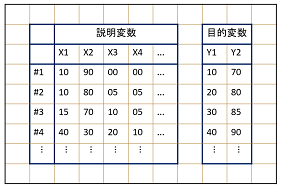
学習対象のデータセット形状イメージとしては、左上の画像のようなテーブルに記述されており、加えてそれぞれのセルに色が割り振られていました。
また、データ形式は表計算ソフトで使用されるファイルでした。 このような場合の課題としては、 説明変数と目的変数のテーブルが分かれている、日本語表記が入っている、#(シャープ)によるナンバリング、表上にある空白行、セルの色に対する処理が挙げられます。 これによって、日本語表記によるエンコードエラー、シャープ部分と空白部分を取り除くなどのひと手間を加える必要が出てきます。 従来の機械学習はこれをコーディングで行わなければなりません。 この作業をPipeline Pilotはワークフローに組み込むことが出来るため、効率的かつ簡潔な機械学習のワークフローが実現されました。 |
||
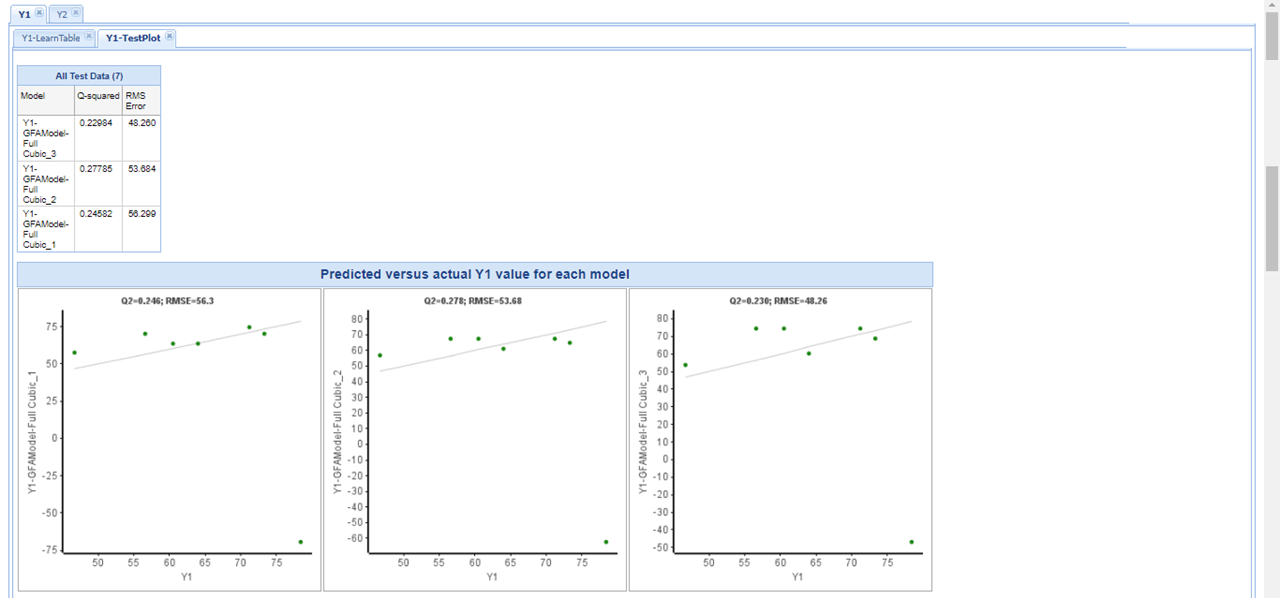
| その「データ整形と機械学習を同時に行うフロー」をPipeline Pilotで実現したものが右上画像(クリックで拡大)のフローとなっています。 このフローによって、「データを読み取り、機械学習を行い、検証を行い、レポート出力する」が実行されます。 ワークフローその1によって作成された機械学習モデルは、検証結果からまだ改善の余地があると判断できるものでした。 そのため、機械学習モデルの精度改善に向けた提案を弊社から挙げさせていただきました。それによって得られたモデルの比較を次項で行います。 | ||
ワークフローその2と結論、今後の活用先
|
|
|
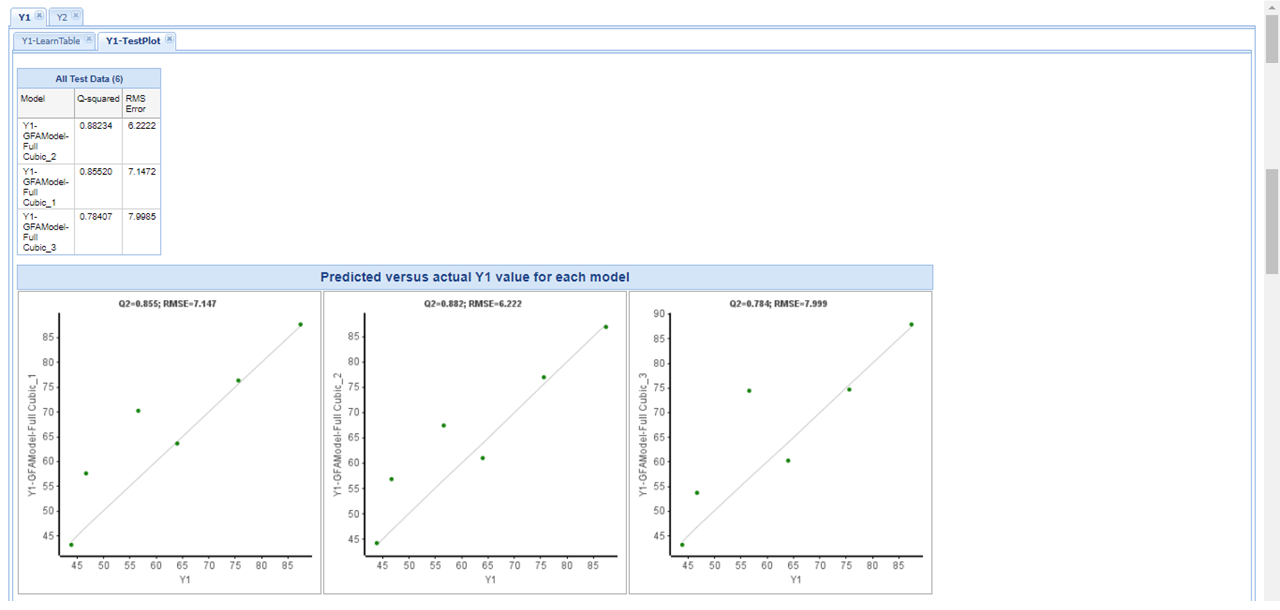
「ワークフローその1」の結果を踏まえ、精度改善前の検証結果(左画像:クリックで拡大)と精度改善後の検証結果(右画像:クリックで拡大)を上に示します。
Pipeline Pilotの特徴としては、作成したワークフローの保存や配布も可能であることが挙げられます。
この特徴を生かして、機械学習条件は前回と同様、ワークフローも同様のものを使用いたしました。 このふたつを比較すると、改善することによって大きな外れ値をなくすことができ、かつ実測値と予測値の傾向もほぼ同じにできているということが出来ます。 |
|
| 今回のベンチマークシミュレーションにおいては、まずPipeline Pilotの強みのひとつである「簡単に機械学習を行うこと」を生かし、 機械学習モデルの作成、予測精度の改善まで実現されました。 また、作成された学習モデルの活用先には「特性値を予測することで最適な実験条件の傾向を掴むこと」が一番に挙げられました。 | |