
トップページ > 設備保全管理ソリューション > 信頼性へのベイズ統計・MCMC法の活用
ベイズ統計・MCMC法を利用した信頼度・故障率の推定
1. 故障時間データ, 及び, 階層ベイズを活用した信頼度の推定
1.1. 信頼性関数[1][2]
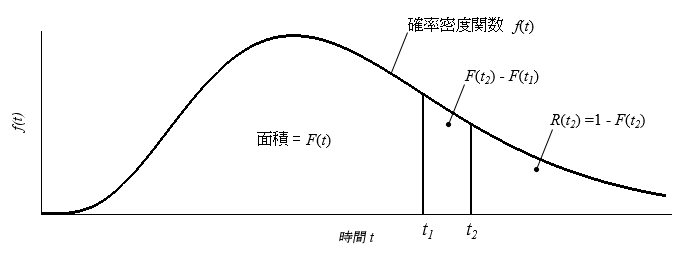
故障時間(failure time) $t$ は, 確率密度関数 $f(t)$, 累積密度関数 $F(t)$, 信頼度関数 $R(t)$, または, ハザード関数 $h(t)$ (A.1節)を使用して特長づけることができます. 確率密度関数 $f(t)$ は, 着目する機器の故障時間の頻度分布として用いられます. 累積密度関数 $F(t)$ は, 時間間隔 $0 - t$ において, 機器が故障する確率を与えます. 別の言い方をすると, $F(t)$ は, 時間 $t$ までに故障する機器の割合を示し, 不信頼度関数とも呼ばれます. $F(t_2)-F(t_1)$ は, 下図の $f(t)$ 及び $t = t_1, t_2$ で囲まれる面積を示し, 次のような解釈が挙げられます.
- $F(t_2)-F(t_1)$: ある機器が, 時間 $t_1$ まで生存し, その後, 時間 $t_2$ までに故障する確率.
- $F(t_2)-F(t_1)$: 時間間隔 $t_2 - t_1$ の間に故障する機器の割合.
信頼度関数 $R(t)$ は, 時間 $t$ において生きている確率を示し, 次式のように書けます: $R(t) = 1 - F(t)$. 信頼度については, 次のような解釈が挙げられます.
- $R(t)$: ある機器が, 時間 t において生きている確率.
- $R(t)$: 少なくとも時間 t まで生きる機器の(全体に対する)割合.
1.2. 階層ベイズを活用した信頼度 $R(t)$ の推定例[3]
故障時間データ
階層ベイズを活用した信頼度の推定例をご紹介します(文献[3]より抜粋). 本例では, 次のようなローラーベアリングの故障時間データ[h]を用います(画像はイメージです). アスタリスク(*)が付いているデータは右側打ち切りデータであり, 付いていないものは打ち切り無しの故障時間です.
|
 |
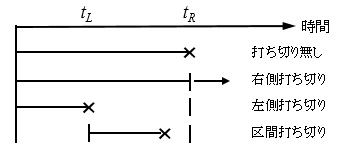
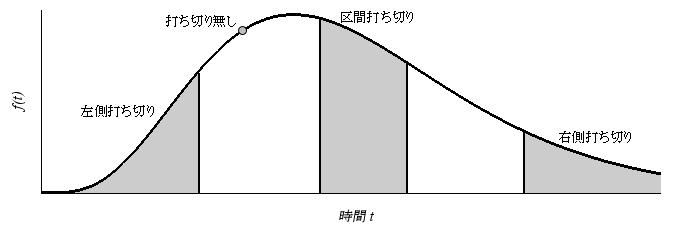
ここで, 打ち切りデータとは, 次のようなデータを指します.
- 打ち切り無し: 故障時間がわかっている(データの値 = 故障時間).
- 右側打ち切り: 点検の時点では, 故障は生じていない.
- 左側打ち切り: 点検の時点で, 既に, 故障していた.
- 区間打ち切り: ある時間区間において故障した.
尤度関数
ベイズ統計では, 事前分布, 事後分布, 及び, 尤度関数の関係は, 次のように書けます(A.3節).
$ \hspace{20pt}事後分布 \propto 尤度関数 \times 事前分布 \\ $上図のように, 点検を実施した時刻を $t_L$, $t_R$ と書くと, 各観測タイプにおける故障時間 $t$ , 及び, 尤度関数における項は次のように書くことができます.
|
本例では, $f(t)$ が対数正規分布に従うものと仮定します. 11個の打ち切りなしデータと, 55個の右側打ち切りデータを使用すると, 尤度関数は, 次式のように書けます.
$ \hspace{20pt}f(\pmb{t}_{u},\pmb{t_c}|\mu, \sigma^2) = \prod^{n=11}_{i=1} f(\pmb{t}_{u,i}|\mu, \sigma^2) \prod^{n=55}_{j=1} (1-F(\pmb{t}_{c,j}|\mu, \sigma^2)) \\ $ここで, $\pmb{t}_{u,i}, 及び, \pmb{t}_{c,j}$ は, それぞれ, $i$ 番目の打ち切り無しデータ, 及び, $j$ 番目の右側打ち切りデータを表します. また, $\mu$, 及び, $\sigma^2$ は, それぞれ, 対数正規分布の平均, 及び, 分散です.
事前分布
$\mu$, 及び, $\sigma^2$ の事前分布は, 次のような, 正規分布, 及び, 逆ガンマ分布を採用しています(文献[3]では, この選択を, 機器の技術者の知見に基づいて決めたとしています).
- $\mu \sim Normal(6.5, 25)$
- $\sigma^2 \sim InverseGamma(6.5, 23.5)$
試計算
以上の内容を踏まえると, 事前分布, 尤度関数, 及び, 事後分布は, 次のように書けます.
$ \hspace{20pt}事後分布 \propto 尤度関数 \times 事前分布\\ \hspace{20pt}f(\mu, \sigma^2|\pmb{t}_{u},\pmb{t_c}) \propto f(\pmb{t}_{u},\pmb{t_c}|\mu, \sigma^2) p(\mu) p(\sigma^2) \\ $- $p(\mu)p(\sigma^2)$: $\mu$, 及び, $\sigma^2$ は, それぞれ, 正規分布, 及び, 逆ガンマ分布に従うものとする.
- $f(\pmb{t}_{u},\pmb{t_c}|\mu, \sigma^2)$: $\mu$, 及び, $\sigma^2$ がある値をとるとき, 故障時間が $\pmb{t}_{u},\pmb{t_c}$ となる確率は, 対数正規分布から求められるとする.
- $f(\mu, \sigma^2|\pmb{t}_{u},\pmb{t_c})$: データ $\pmb{t}_{u},\pmb{t_c}$ が与えられたとき, 上の関係を満たすような, $\mu$ 及び $\sigma^2$ の確率分布.
本例では, MCMC(Markov chain Monte Carlo)のアルゴリズムを搭載したソフトウェアを使用し, $\mu$ 及び $\sigma^2$ の確率分布, 及び, 信頼度関数 $R(t)$ (1.1節)の試計算を試みました. 信頼度関数 $R(t)$ の算出例を下図に掲載します. 各時刻における信頼度(分布)の中央値を実線で示しています. 90%信頼区間を点線で示しています.
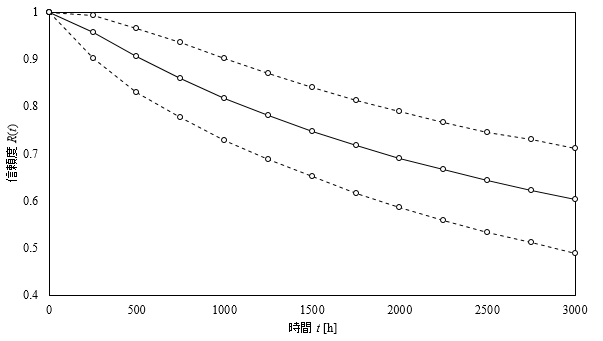
この例では, 打ち切り無し・打ち切り有りの故障時間データが混在する場合について, 信頼性関数推定の試計算例を記しました. このように, 異なる打ち切りの方式が混在した故障時間データをまとめて考慮した上で, 信頼性関数推定の検討が可能な点は, ベイズ統計の枠組みを用いる利点であると言えます.
2. カウントデータ, 及び, 階層ベイズを活用した故障率の推定[3]
故障のカウントデータ
故障のカウントデータを使用した故障率の推定例を記します(文献[3]より抜粋). この例では, 47個の同種の機器(スーパーコンピュータのメモリ)について, 1ヶ月当りの故障回数を使用します(画像はイメージです).
|
 |
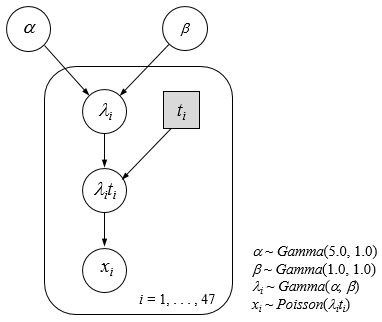
階層ベイズの構成
本例では, 機器の故障はランダムに発生すると想定し, 故障率(ハザード関数: A.1節)は一定とします. 各機器の1ヶ月当りの故障回数 $x_i$ はポアソン分布(A.2節)に従うものと仮定します. $\lambda_i$ を機器 $i$ の故障率[回/月], $t_i$ を機器 $i$ の稼動時間(=1ヶ月)すると, 次のように書けます.
$ \hspace{20pt}x_i \sim Poisson(\lambda_i t_i)\hspace{40pt}i=1,...,47\\ \\ $故障率は, ガンマ分布(A.2節)に従うものと仮定します.
$ \hspace{20pt}\lambda_i \sim Gamma(\alpha, \beta)\hspace{40pt}i=1,...,47\\ \\ $文献[3]では, ハードウェアに関する知見に基づき, ハイパーパラメータ $\alpha, \beta$ を次のように与えています.
$ \hspace{20pt}\alpha \sim Gamma(5.0, 1.0)\\ \hspace{20pt}\beta \sim Gamma(1.0, 1.0)\\ \\ $
試計算
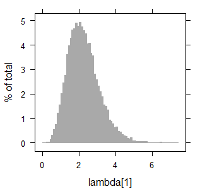
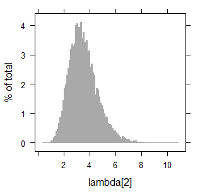
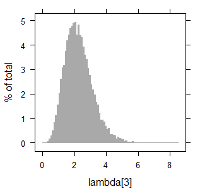
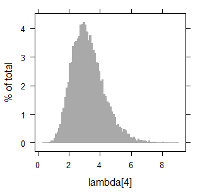
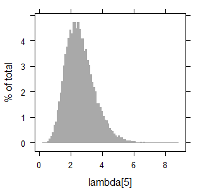
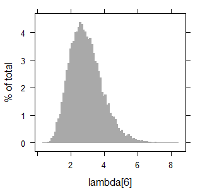
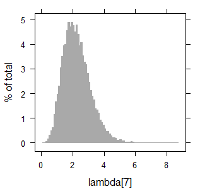
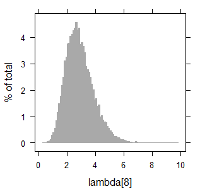
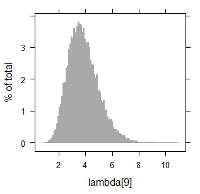
MCMC(Markov chain Monte Carlo)のアルゴリズムを搭載したソフトウェアを使用し, 上記の関係を満たすような各パラメータ推定の試計算例を記します. 以下に $\lambda_i$ に関する数値データ, 及び, ヒストグラムを掲載します. 例えば, $\lambda_1$ 及び $\lambda_9$ に着目すると, 次のように書けます.
- $\lambda_1$ の故障回数は, 比較的少なく, 1回のみである. 一方, 計算結果では, 平均2.24の故障率(分布)となっている.
- $\lambda_9$ の故障回数は, 比較的多く, 6回である. 一方, 計算結果では, 平均3.84の故障率(分布)となっている.
上記のような試計算結果は, 簡単に書くと, 次のように解釈できます: 個々の故障率を推定する際, 自身以外の(全ての)機器のデータ(故障回数)を考慮・評価して実施されます. この点は, 階層ベイズを活用する利点であると言えます. また, 各故障率についての分布が得られる為, 区間(例: 90%信頼区間)で評価することも検討可能と言えます.
| 下側95% | 中央値 | 上側95% | 平均 | 標準偏差 | |
| lambda[1] | 0.7514109 | 2.147105 | 4.022371 | 2.248174 | 0.86767 |
| lambda[2] | 1.6051606 | 3.393372 | 5.794147 | 3.526564 | 1.1029097 |
| lambda[3] | 0.7159811 | 2.164982 | 3.984437 | 2.260034 | 0.8687029 |
| lambda[4] | 1.3097501 | 3.094269 | 5.308 | 3.217656 | 1.0454095 |
| lambda[5] | 0.9313061 | 2.469935 | 4.413017 | 2.584402 | 0.9256131 |
| lambda[6] | 1.1088179 | 2.790464 | 4.791722 | 2.89844 | 0.9844707 |
| lambda[7] | 0.7862549 | 2.161655 | 4.031876 | 2.261437 | 0.8676789 |
| lambda[8] | 1.1637672 | 2.775239 | 4.87893 | 2.894845 | 0.9850045 |
| lambda[9] | 1.7266852 | 3.702908 | 6.105735 | 3.837611 | 1.1579164 |
・・・以降省略
・・・以降省略
A. 付録
A.1. ハザード関数(瞬間故障率, 故障率)[2]
時間 t = 0 から稼動を開始する1000個の機器を想定します. 時間の経過と共に, 機器は, 一つ一つ, 故障していくことが考えられます. 例えば, 5000時間稼動し, 4個の機器が故障したとします. このとき, 次の機器が, 5000-5001時間の間に故障する確率を考えます. t = 5000 において996個の機器が稼動しており, 次の1時間に機器が(1個)故障するので, その故障率は, 次のような見積もりが考えられます: 1/996 [個/時間]. この見積もり式をよく見てみますと, 条件付確率が考慮されていることがわかります. 具体的には, "5000時間後に生き残った機器(=996個)の内" という条件です.
このような条件を考慮した確率は, 条件付確率を用いてより正確に定義されます. $A$ が生じた後(条件: 上の例では, 5000時間稼動して, 996個が生き残っている), $B$ が起こる(上の例では, 5000-5001時間の間に1個の機器が故障する)確率は, 次式のように書けます.
$ \hspace{20pt}P(B|A) = \frac{P(B と A が共に起こる)}{P(A)} \\ $この式を用いると, 時間 $t$ まで生存し, 次の(小さい)時間間隔 $\Delta t$ において故障する(条件付き)確率は, 次式のように書けます.
$ \hspace{20pt}P(次の \Delta t において故障する|時間 t まで生きる) = \frac{F(t + \Delta t) - F(t)}{R(t)} \\ $上式を $\Delta t$ で割り, 単位時間当りの値(=割合)に変換します.
$ \hspace{20pt}P(次の単位時間において故障する|時間 t まで生きる) = \frac{F(t + \Delta t) - F(t)}{R(t)\Delta t} \\ $ここで, $\Delta t \rightarrow 0$ とすると, 次式のようになります.
$ \hspace{20pt}\lim_{\Delta t \to 0}\frac{F(t + \Delta t) - F(t)}{R(t)\Delta t} = \frac{F'(t)}{R(t)} = \frac{f(t)}{R(t)} \\ $上式の左辺は, ハザード関数と呼ばれ(または, 瞬間故障率, 或は, 単に故障率と書かれる), 時間 $t$ まで生きた後, 次の(微小)時間に故障する機器の割合を示します.
$ \hspace{20pt}h(t) = \frac{f(t)}{R(t)} \\ $ハザード関数は, 上の式で表される割合であり, 1より大きい値をとり得ます. また, 次の点に注意が必要です: 文献によって, 故障率の定義が異なる場合があるようです. 例えば, 故障率の定義を $f(t)$ としているものもあります.
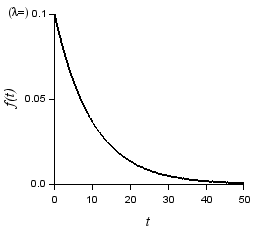
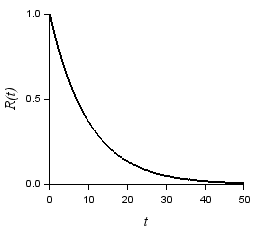
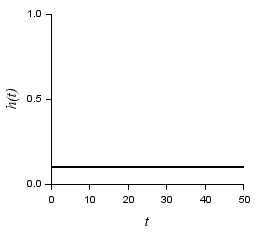
例として, ハザード関数(または故障率)を一定($\lambda = 0.1$)としたときの確率密度関数(指数分布)$ f(t)$, 信頼度関数 $R(t)$, 及び, ハザード関数(または故障率)を以下に示します.
| $f(t) = \lambda e^{-\lambda t}$ | $R(t) = e^{-\lambda t}$ | $h(t) = \lambda$ |
 |
 |
 |
A.2. 確率分布
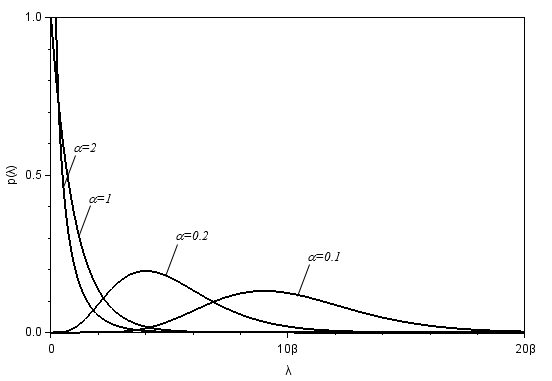
ガンマ分布[6]
ガンマ分布は指数分布を一般化したものである. 故障率を表現する確率分布として広く使用されている. ガンマ分布が, 故障率の表現として受入れられている主な理由は, (例えば, ポアソンサンプリングモデルにおける)自然な共役分布であることが挙げられる. ガンマ分布 $Ga(\alpha, \beta)$ の確率密度関数は次式のように書ける.
$ \hspace{20pt}p(\lambda;\alpha,\beta) = \frac{\beta^\alpha}{\Gamma(\alpha)}\lambda^{\alpha-1}e^{-\beta\lambda}\hspace{20pt}\lambda, \alpha, \beta \gt 0 \\ $積分して1になる(規格化)ように, $\Gamma(\alpha)$ で割ってある.
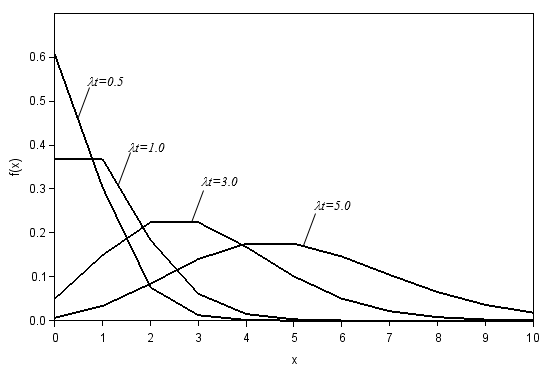
ポアソン分布[4][5], 及び, ポアソン過程
ポワソン分布はある時間内, 空間内, 及び, 面積内に生じる事象数のモデル化に広く使用されている. 例えば, ワイヤーや計算機の磁器テープの欠陥, または, ある期間における製品の故障数などである. このモデルは, 次のような状況で使用される.
- 期間に亘って, 各々の事象は, 独立に発生する.
- どの時間においても, 事象は, 同じ確率で発生する(偶発的に発生する).
- 事象の発生数は, 制限されない(the potential number of occurrences is essentially unlimited).
標本 $X$ は, 非負の整数であり, その標本空間は $S={0, 1, 2, ...}$ である. 例えば, 時間区間 $(0, t)$ において生じる事象の数を, $X(t)$ と書くこととする. このとき, $X(t) (t \ge 0)$ の乱数は, しばしば, ポアソン分布に従うものと仮定される. また, このとき, $X(t) (t \ge 0)$ は, 強度(intensity) $\lambda$ のポアソン過程であると呼ばれる.
$ \hspace{20pt}f(x) = \frac{(\lambda t)^{x}e^{-\lambda t}}{x!}\hspace{20pt}\lambda \gt 0,\hspace{20pt}x = 0, 1, 2, ... \\ $- $x$: 時間区間(0, t)における事象(発生)数.
- $\lambda$: 単位時間当たりの(平均)事象(発生)数.
- $t$: 時間.
- $f(x)$: 確率.
A.3. ベイズ統計学について[7]
母数 $\theta$ の母数空間を $\Theta$, 観測される確率変数 $\tilde x$ の標本空間を $\Omega$ とする.
- $\theta$ について, 既知の確率分布があるものとする(事前分布と呼ぶ). その密度関数を $p(\theta)$ とする.
- 観測される確率変数 $\tilde x$ は, 母数 $\theta$ が真であるとき, $\Omega$ 上の密度関数 $f(x|\theta)$ を持つものとする. ($f(x|\theta)$ は条件付確率と呼ばれる. 簡単に書くと次のような意味である: $\theta$ のとき, $x$ が起こる確率)
- さらに, $f(\theta, x)$ を, $\Theta \times \Omega$ 上の確率変数 $\tilde{\theta}, \tilde x$ の同時密度関数とする. (このとき, $f(\theta, x) = p(\theta)f(x|\theta)$ と書ける)
1. によって, 母数空間 $\Omega$ 上に確率分布が導入されていれば, 観測による標本情報 $\tilde{x} = x$ が得られたという条件のもとでは, ベイズの定理により, $\Omega$ 上に次のような密度関数を持つ新たな(条件付)確率分布が定まる.
$ \hspace{20pt}p(\theta|x) = \frac{f(\theta, x)}{f(x)} \\ \hspace{45pt} = \frac{p(\theta)f(x|\theta)}{\int_{\Theta}f(\theta,x)d\theta} \\ \hspace{45pt} = \frac{p(\theta)f(x|\theta)}{\int_{\Theta}p(\theta)f(x|\theta)d\theta} \\ \\ $$p(\theta|x)$ は事後分布と呼ばれる. また, $f(x|\theta)$ を, $x$ が与えられたときの $\theta$ の関数とみれば, これは尤度関数である. よって, 上の式より, 次式のようにも表せる.
$ \hspace{20pt}事後分布 \propto 尤度関数 \times 事前分布 \\ $