活用例
 風力発電量のモデリング
風力発電量のモデリング

風力は、従来の化石燃料に代わるクリーンな代替エネルギーです。 風車の発電量は、理論上は方程式を用いて簡単に計算できます。 しかし、理想的な状況を仮定した理論上のモデルを超えて、実験的な要素を考慮したより現実的な予測をしようとすれば、機械学習の出番となります。
この例では、実際の風車のデータをもとに発電量を予測するモデルを構築します。
リンク:
 アプリケーションの選択
アプリケーションの選択
予想する変数(発電量)は連続的なので、近似モデルとなります。
この事例の主な目標は、風速の関数として発電量をモデル化することです。
 データセットの設定
データセットの設定
最初のステップは、近似モデルの情報源であるデータセットの準備です。 データセットは以下で構成されています。
- データソース
- 変数
- インスタンス
このデータセットでは、変数の数(列数)は2個、インスタンスの数(行数)は48007個です。 変数は以下の通りです。
入力
- 風速[m/s]
ターゲット
- 瞬間発電量[kW]
このデータセットを訓練用、検証用、テスト用に分割します。 それぞれがインスタンス全体の60%、20%、20%を含むようランダムに分けます。
データの正確性の確認や異常の発見のために、分布を計算しておきます。
下の図は発電量のヒストグラムです。
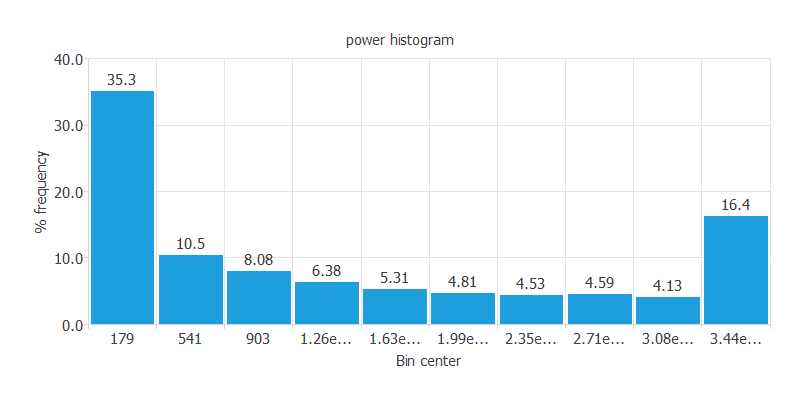 発電量の大きいものと小さいものに分布が偏っています。
発電量の大きいものと小さいものに分布が偏っています。
ターゲットの入力への依存性を調べることも有用です。
そのために、入力とターゲットの間の相関を計算できます。
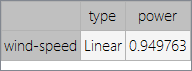 表の右下の値が相関値です。
期待通り、"wind-speed: 風速"は"power: 発電量"と強く相関しています。
表の右下の値が相関値です。
期待通り、"wind-speed: 風速"は"power: 発電量"と強く相関しています。
また次の図は、風速と発電量の散布図です。
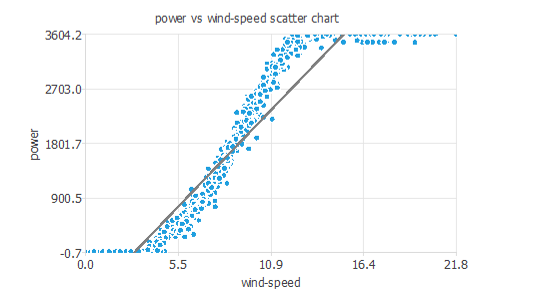 風速がある閾値を超えると、発電量は上限値まで線型に増加していくことが見て取れます。
その後、上限値に達すると、風速がどれほど大きくても発電量は一定の値をとっています。
風速がある閾値を超えると、発電量は上限値まで線型に増加していくことが見て取れます。
その後、上限値に達すると、風速がどれほど大きくても発電量は一定の値をとっています。
 ネットワーク構造の設定
ネットワーク構造の設定
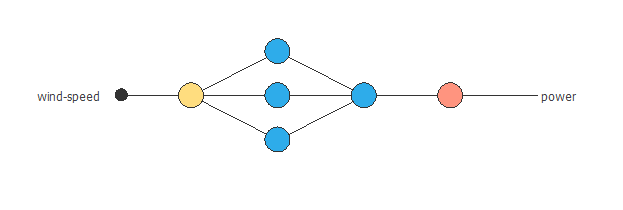
次のステップはニューラルネットワークの構造の設定です。 近似モデルでは通常、ニューラルネットワークは次のように構成されます。
- スケーリング層
- パーセプトロン層
- アンスケーリング層
スケーリング層
スケーリング層は入力の統計情報を含みます。 この例では、自動設定を用いて最適なスケーリング手法を調整します。
パーセプトロン層
この例では、2つのパーセプトロン層を用います。 1層目は1つの入力を持つ3つのニューロンで、2層目は3つの入力を持つ1つのニューロンです。 1層目、2層目それぞれの活性化関数は双曲線正接関数と線型関数に設定します。
アンスケーリング層
アンスケーリング層は、ターゲットの統計情報を含みます。 ここでも自動設定を用います。
次の図は、この例のニューラルネットワークの構造を表しています。
 学習手法の設定
学習手法の設定
次のステップでは、学習手法を選択します。 一般的な学習手法は、次2つのコンセプトで構成されています。
- 損失関数
- 最適化アルゴリズム
損失関数
損失関数は、ニューラルネットワークが何を学習するかを規定し、誤差項と正則化項から成ります。
この例では、誤差項には正規化二乗誤差を選びます。 ニューラルネットワークの出力値と実際のターゲットの値との二乗誤差を正規化係数で割ったものです。 正規化二乗誤差が1ならばニューラルネットワークは”平均的に”データを予測しており、0ならば完全にデータを予測しています。 この誤差項には設定するパラメータはありません。
正則化項にはL2正則化を選択します。 この項は変数のパラメータを減らしてニューラルネットワークの複雑性を制御するために用います。 正則化項には弱い重みをつけます。
最適化アルゴリズム
最適化アルゴリズムは、損失関数を最小化するニューラルネットワークのパラメータを探索する役目を担います。 ここでは準ニュートン法を選択します。
学習手法の設定が終わったら、ニューラルネットワークに学習をさせます。
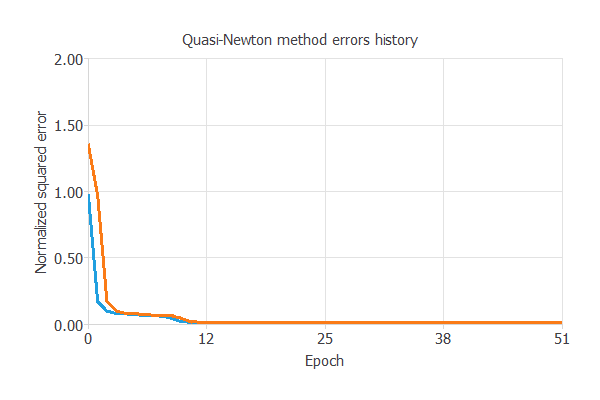
下の図は、学習過程において、エポック数(学習の繰り返し回数)の増加とともに訓練誤差(青)と検証誤差(オレンジ)がどのように減少していくかを示したものです。
最終的な値はそれぞれ、訓練誤差=0.00857NSE、検証誤差=0.00869NSEです。
 モデル選択
モデル選択
モデル選択アルゴリズムは、ニューラルネットワークの汎化性能を改善するために用いられます。
ここまでに達成した検証誤差が非常に小さい(0.00869NSE)ため、この例ではモデル選択アルゴリズムは必要ありません。
 テスト分析
テスト分析
テスト分析の目的は、ニューラルネットワークの汎化性能を評価することです。 これまでに使用していない、テスト用インスタンスを使います。
近似モデルでの標準的なテスト手法は、モデルの出力値と実際の値の間の線型回帰分析を行うことです。
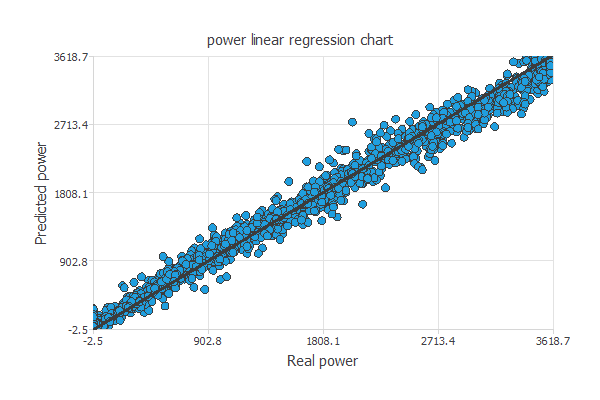 完全な予測の場合、相関係数R2は1となります。
この例の値はR2=0.996なので、テスト用データを非常によく予測できています。
完全な予測の場合、相関係数R2は1となります。
この例の値はR2=0.996なので、テスト用データを非常によく予測できています。
 モデルの利用
モデルの利用
モデルを利用する際には、見たことのない入力値に対してターゲットを予測します。 たとえば、
- 風速: 7.465[m/s]
- 発電量: 1166.580[m/s]
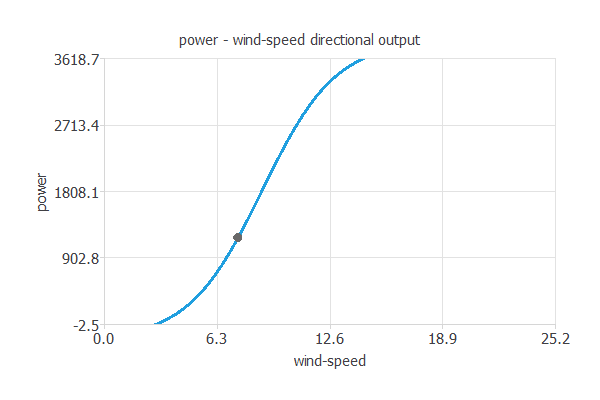
また、Directional outputを用いて、ある基準点を通る出力の変化をプロットできます。
上の値を基準点とした際のプロットが以下の図です。
これにより発電量への風速による影響を見ることができます。
最後に、設計者による理論的な計算における平均二乗誤差と、このモデルにおける平均二乗誤差を比較したものが以下の表です。
 設計者による理論計算の値(1.95%)と、このモデルの値(1.41%)を比較することで、この適用例の真価が明らかになります。
平均二乗誤差は、相対的に27.69%改善されています。
したがってこのモデルは、物理的な近似の代わりに実測データを鑑みることで、より良い性能を実現していると言えます。
設計者による理論計算の値(1.95%)と、このモデルの値(1.41%)を比較することで、この適用例の真価が明らかになります。
平均二乗誤差は、相対的に27.69%改善されています。
したがってこのモデルは、物理的な近似の代わりに実測データを鑑みることで、より良い性能を実現していると言えます。