活用例
 太陽光発電量の時系列予測
太陽光発電量の時系列予測

太陽光発電は、従来の化石燃料に取って代わるクリーンな代替エネルギーです。 しかし現時点では、太陽電池の発電効率は私たちが望むほど高くありません。 したがって、太陽光発電で最大限のエネルギーを得るために、理想的な設置条件を選択することが重要になります。
この例では、いくつかの環境条件を元に、特定の設置状態での発電量を予測します。
リンク:
 アプリケーションの選択
アプリケーションの選択
予想する変数(発電量)は連続的なので、近似モデルとなります。
この事例の主な目標は、発電量を環境変数の関数としてモデル化することです。
 データセットの設定
データセットの設定
最初のステップは、近似モデルの情報源であるデータセットの準備です。 データセットは以下で構成されています。
- データソース
- 変数
- インスタンス
このデータセットでは、変数の数(列数)は10個、インスタンスの数(行数)は2920個です。 変数は以下の通りです。
入力
- 太陽の最高到達点との距離[rad]
- 日平均気温[℃]
- 日平均風向[°]
- 日平均風速[m/s]
- 雲量[0を全天晴れ、4を全天曇りとした5段階評価]
- 視程[km]
- 湿度[%]
- 3時間平均風速[m/s]
- 3時間平均気圧[inHg]
ターゲット
- 発電量[J]
このデータセットを訓練用、検証用、テスト用に分割します。 それぞれがインスタンス全体の60%、20%、20%を含むようにランダムに分けます。
データ分布を計算することで、データの正確性を確認し異常を検出することができます。
下の図は、発電量のヒストグラムです。
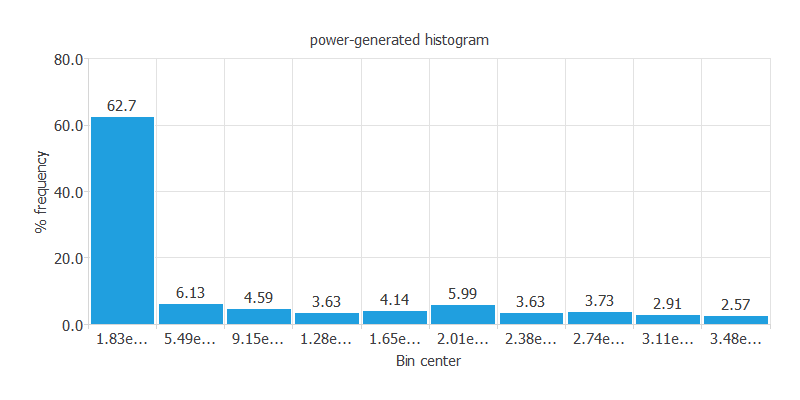 見ての通り、圧縮強度の分布は正規分布になっています。
見ての通り、圧縮強度の分布は正規分布になっています。
1つの入力と1つのターゲットの間の依存性を調べるのも重要です。
そのために、各入力とターゲットの間の相関を図示します。
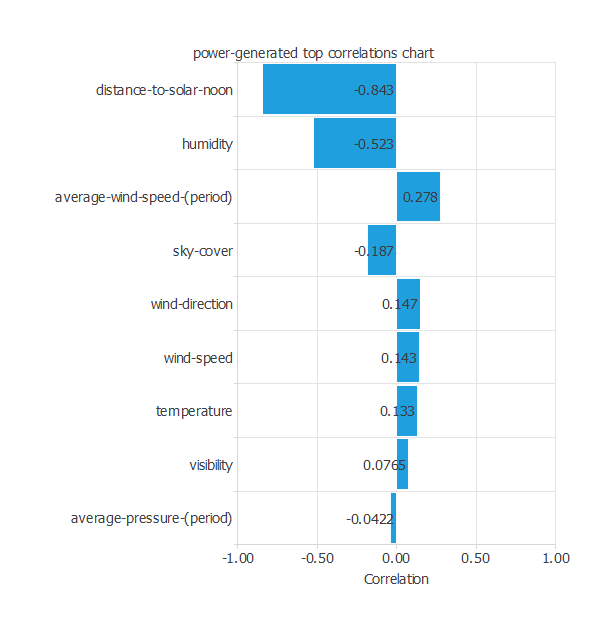 この事例の場合、ターゲットとの相関が最も強い入力は、"distance-to-solar-noon: 太陽の最高到達点との距離"です(太陽が最高到達点に近いほど、発電量も大きくなります)。
この事例の場合、ターゲットとの相関が最も強い入力は、"distance-to-solar-noon: 太陽の最高到達点との距離"です(太陽が最高到達点に近いほど、発電量も大きくなります)。
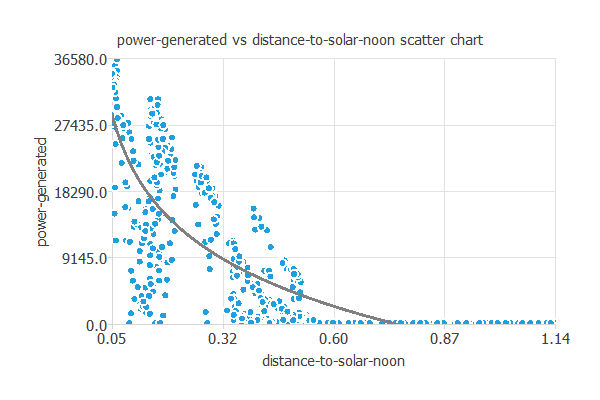
ターゲットと最も相関が強い入力(太陽の最高到達点との距離)との散布図を図示します。
 ネットワーク構造の設定
ネットワーク構造の設定
次のステップはニューラルネットワークの構造の設定です。 近似モデルでは通常、ニューラルネットワークは次のように構成されます。
- スケーリング層
- パーセプトロン層
- アンスケーリング層
スケーリング層
スケーリング層は、入力の統計情報を含みます。 この例では、自動設定を使ってデータに合ったスケーリング手法を調整します。
パーセプトロン層
この例では、2つのパーセプトロン層を使います。 1つ目の層は、9つの入力を持つ3つのニューロンで、活性化関数は双曲線正接関数です。 2つ目の層は、3つの入力を持つ1つのニューロンで、活性化関数は線型関数です。
アンスケーリング層
アンスケーリング層は、ターゲットの統計情報を含みます。 ここでも自動設定を用います。
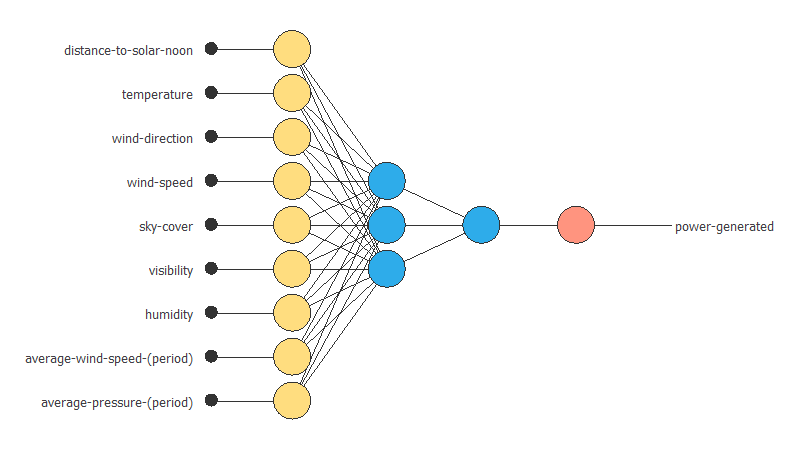
次の図は、この例のネットワーク構造を表しています。
 学習手法の設定
学習手法の設定
次のステップでは、学習手法を選択します。 一般的な学習手法は、2つのコンセプトで構成されています。
- 損失関数
- 最適化アルゴリズム
損失関数
損失関数はニューラルネットワークが何を学習するかを規定し、誤差項と正則化項から成ります。
ここでの誤差項には正規化二乗誤差を選びます。 ニューラルネットワークの出力値と実際のターゲットの値との二乗誤差を正規化係数で割ったものです。 正規化二乗誤差が1ならばニューラルネットワークは”平均的に”データを予測しており、0ならば完全にデータを予測しています。 この誤差項には設定するパラメータはありません。
正則化項はL2正則化とします。 この項は、パラメータを減らしてニューラルネットワークの複雑性を制御するために用います。 正則化項には弱い重みをつけます。
最適化アルゴリズム
最適化アルゴリズムは、損失関数を最小化するパラメータの探索を担います。 ここでは、最適化アルゴリズムとして準ニュートン法を採用します。
下の図は、学習過程においてエポック数(繰り返し回数)が増すごとに訓練誤差(青)と検証誤差(オレンジ)がどのように減少していくかを示しています。
最終的な値はそれぞれ、訓練誤差=0.121NSE、検証誤差=0.122NSEです。
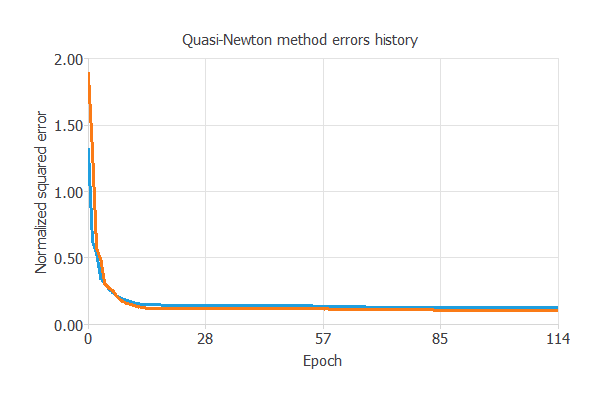 トレーニングの結果で最も重要なのは、最終的な検証誤差(0.122NSE)です。
これがニューラルネットワークの汎化性能の指標となります。
トレーニングの結果で最も重要なのは、最終的な検証誤差(0.122NSE)です。
これがニューラルネットワークの汎化性能の指標となります。
 モデル選択
モデル選択
モデル選択の目的は、最良の汎化性能を持つネットワークアーキテクチャを見つけることです。 つまり、先ほどの最終的な検証誤差(0.122NSE)を改善するのが目的です。
最適な複雑性を備えたモデルを用いることで、最小の検証誤差が実現されます。
そのために用いるニューロン数選択アルゴリズムは、最適なニューロンの数を見つける役割を果たします。
下の図は、ニューロン数選択アルゴリズムの一種であるグローイングニューロンを用いた結果を示しています。
ニューロン数の関数として、青線は最終的な訓練誤差を、オレンジ線は最終的な検証誤差を表しています。
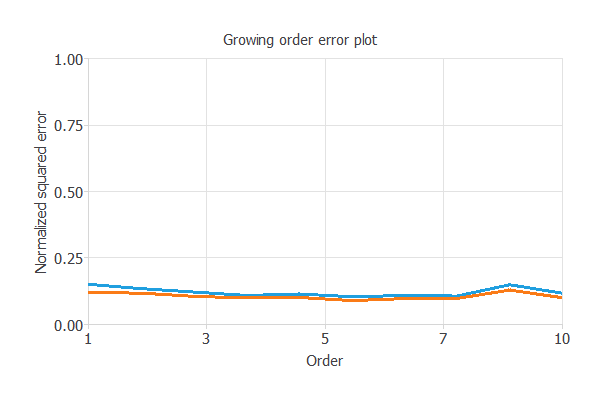 見ての通り、訓練誤差はニューロンの数の増加とともに連続的に減少していますが、検証誤差はある点で最小値をとっています。
ここでの最適なニューロン数は8個で、その時の検証誤差は0.089NSEです。
見ての通り、訓練誤差はニューロンの数の増加とともに連続的に減少していますが、検証誤差はある点で最小値をとっています。
ここでの最適なニューロン数は8個で、その時の検証誤差は0.089NSEです。
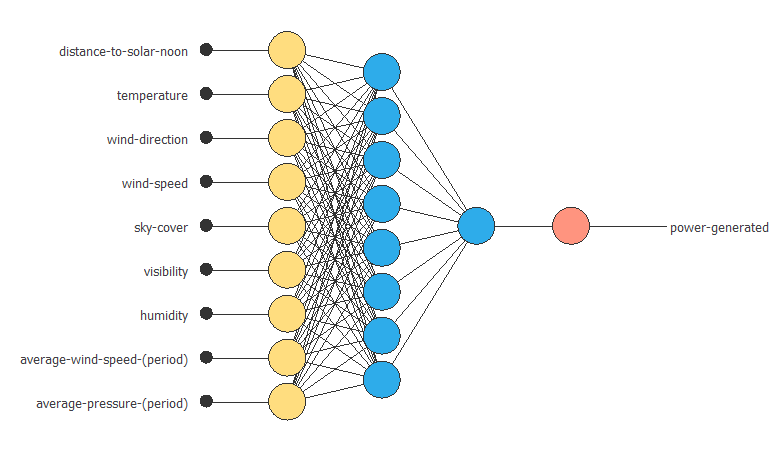
下の図が、この事例での最適なネットワーク構造です。
 テスト分析
テスト分析
テスト解析の目的は、ニューラルネットワークの汎化性能を評価することです。 ここまでに使っていないテスト用インスタンスを使用します。
近似モデルでの標準的なテスト方法は、下の図のように予測値と実際の発電量との間の線型回帰分析を行うことです。
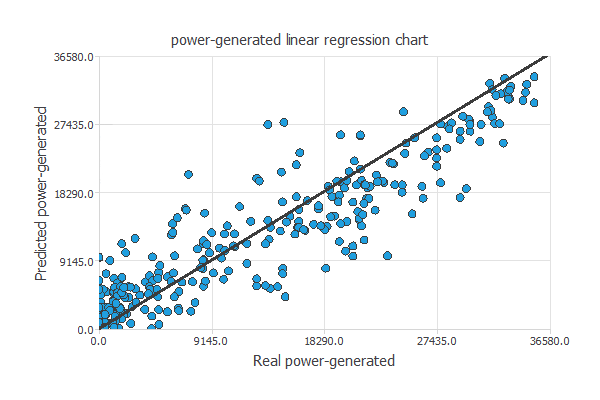 完全な近似では相関係数R2は1になります。
この例の結果は相関係数R2=0.951なので、テストデータを非常によく予測してると言えます。
完全な近似では相関係数R2は1になります。
この例の結果は相関係数R2=0.951なので、テストデータを非常によく予測してると言えます。
 モデルの利用
モデルの利用
モデルを利用する段階では、見たことのない入力値をもとにターゲットを予測します。 たとえば、入力値として
- 太陽の最高到達点との距離: 0.503ラジアン
- 日平均気温: 58.468[℃]
- 日平均風向: 24.953[°]
- 日平均風速: 10.097[m/s]
- 雲量: 1.988 over 4
- 視程: 9.558[km]
- 湿度: 73.524[%]
- 3時間平均風速: 10.136[m/s]
- 3時間平均気圧: 30.062[inHg]
- 発電量: 3012.461[J]
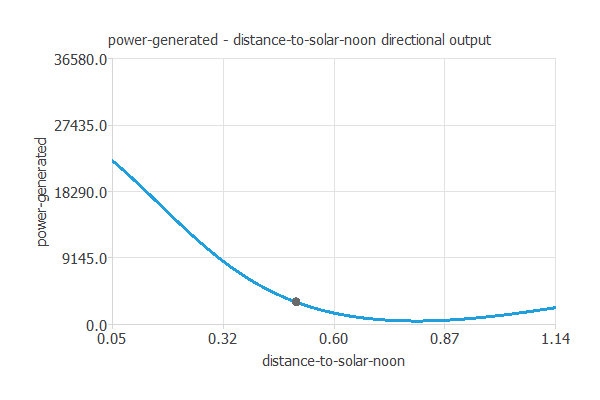 ある値までは、太陽の最高到達点との距離に応じて発電量は減少していき、それ以後は少し上昇に転ずるという振る舞いが見られます。
ある値までは、太陽の最高到達点との距離に応じて発電量は減少していき、それ以後は少し上昇に転ずるという振る舞いが見られます。