活用例
 コンクリートの圧縮強度のモデリング
コンクリートの圧縮強度のモデリング

圧縮強度はコンクリートの最も重要な性能値の一つで、円柱型のコンクリートを圧縮試験機で破壊して計測するのが一般的です。
この事例の目標は、特定の性能を持ちながらもコストが削減できるコンクリートを設計することです。 このために、425個の試料についての実験データをもとに圧縮強度の予測モデルを構築します。 これにより、実際に製造して実験せずともコンクリート強度を予測/シミュレーションできるようになり、開発速度が向上します。
リンク:
 アプリケーションの選択
アプリケーションの選択
予想する変数(圧縮強度)は連続的なので、近似モデルとなります。
この事例の主な目標は、コンクリートの各成分の含有量の関数として圧縮強度をモデル化することです。
 データセットの設定
データセットの設定
最初のステップは、近似モデルの情報源であるデータセットの準備です。 データセットは以下で構成されています。
- データソース
- 変数
- インスタンス
この事例のデータは、8個の列(変数)と、425個の行(インスタンス)を持ちます。 以下がデータ中の変数です。
入力
- セメント含有量[kg/m^3]
- 高炉スラグ含有量[kg/m^3]
- フライアッシュ含有量[kg/m^3]
- 水含有量[kg/m^3]
- 高性能減水剤含有量[kg/m^3]
- 粗骨材含有量[kg/m^3]
- 細骨材含有量[kg/m^3]
ターゲット
- 圧縮強度[MPa]
このデータセットを訓練用、検証用、テスト用に、それぞれがインスタンス全体の60%、20%、20%を含むようにランダムに分割します。
データセットの設定が済めば、データの質を確認するための解析の準備が整います。
例としては、データ分布の計算ができます。
次の図は、圧縮強度のヒストグラムです。
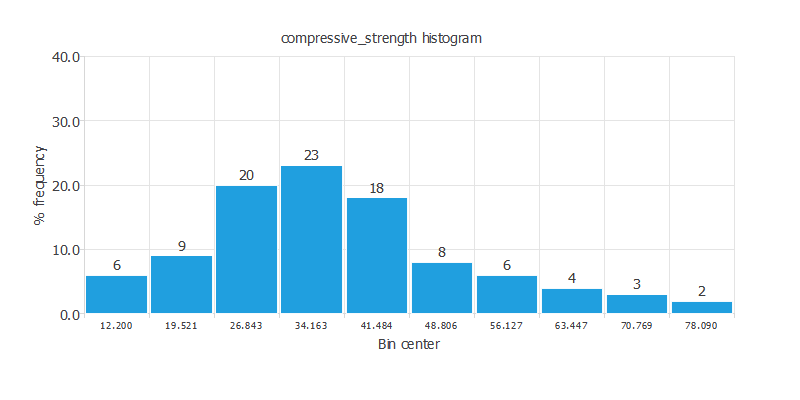 見ての通り、圧縮強度の分布は正規分布になっています。
見ての通り、圧縮強度の分布は正規分布になっています。
次の図は入力と圧縮強度の相関を示しています。
この図は、圧縮強度への各入力の影響の強さを調べるのに役立ちます。
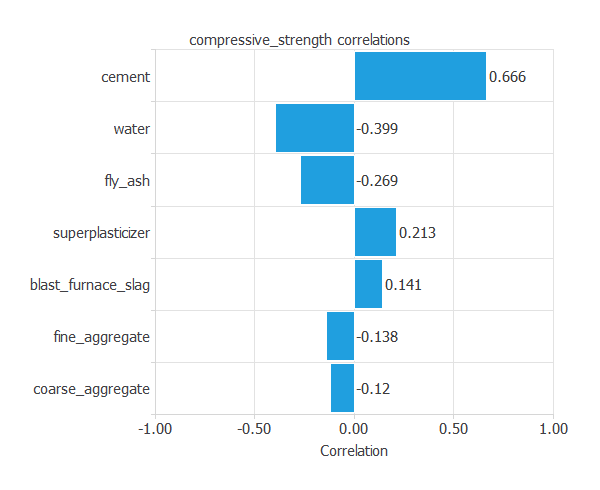 図は、"cement: セメントの量"が圧縮強度に大きな影響を持つことを示しています。
図は、"cement: セメントの量"が圧縮強度に大きな影響を持つことを示しています。
また例えば、圧縮強度と強い相関を持つセメント量との散布図を描くこともできます。
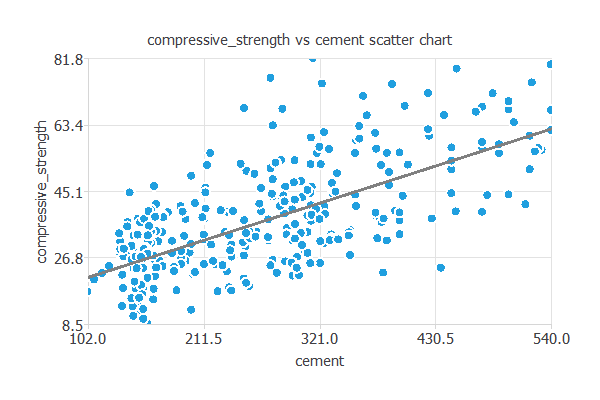 一般に、セメント量が増えるほど圧縮強度も高くなることがわかります。
ただし、圧縮強度は他のすべての入力にも同時に依存しています。
一般に、セメント量が増えるほど圧縮強度も高くなることがわかります。
ただし、圧縮強度は他のすべての入力にも同時に依存しています。
 ネットワーク構造の設定
ネットワーク構造の設定
次のステップはニューラルネットワークの構造の設定です。 近似モデルでは通常、ニューラルネットワークは次のように構成されます。
- スケーリング層
- パーセプトロン層
- アンスケーリング層
スケーリング層
スケーリング層は、入力の統計情報とスケーリング手法を含みます。 ここでは最小値と最大値のスケーリング手法を採用しますが、平均値と標準偏差のスケーリング手法を用いても非常に似た結果を出します。
パーセプトロン層
この事例では、2つのパーセプトロン層を使います。 ほとんどの近似モデルでは、層の数は2層で十分です。 1つ目の層は7つの入力を持つ3つのニューロンで、2つ目の層は3つの入力を持つ1つのニューロンです。 1層目、2層目それぞれの活性化関数は双曲線正接関数と線型関数に設定します。これはデフォルトの設定です。
アンスケーリング層
アンスケーリング層では、ニューラルネットワークから得られる正規化された値を、ターゲットに合わせて変換します。 ここでも最小値と最大値のアンスケーリング手法を使います。
下の図が、この例のニューラルネットワークの構造です。
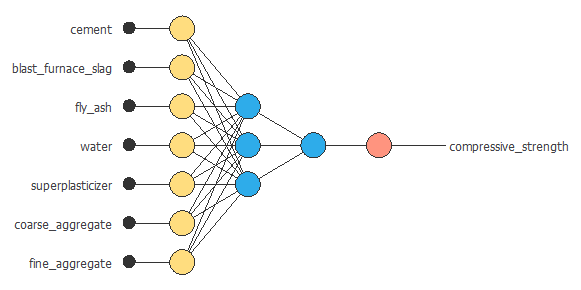
 学習手法の設定
学習手法の設定
次のステップは学習手法の選択です。次の2つの要素からなります。
- 損失関数
- 最適化アルゴリズム
損失関数
損失関数として、誤差項に正規化二乗誤差、正則化項にL2正則化を選びます。
正規化二乗誤差は、ニューラルネットワークの出力値と実際のターゲットの値との二乗誤差を正規化係数で割ったものです。 正規化二乗誤差が1ならばニューラルネットワークは"平均的に"データを予測しており、0ならば完全にデータを予測しています。 この誤差項には設定するパラメータはありません。
L2正則化は、変数のパラメータを減らしてニューラルネットワークの複雑性を制御するために用います。 ここでは正則化項に弱い重みをつけます。
最適化アルゴリズム
この例では、最適化アルゴリズムとして準ニュートン法を用います。
学習手法の設定が完了したら、ニューラルネットワークが最良の性能を得られるように学習をさせます。
下の図は学習の記録を示しています。
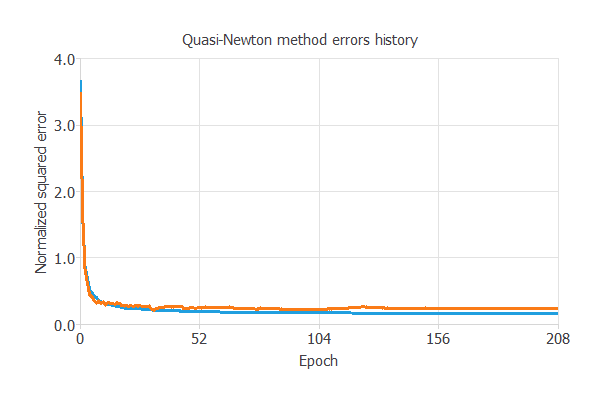 最終的な訓練誤差と検証誤差はそれぞれ、訓練誤差=0.153NSE、検証誤差=0.24NSEです。
最終的な訓練誤差と検証誤差はそれぞれ、訓練誤差=0.153NSE、検証誤差=0.24NSEです。
 モデル選択
モデル選択
データを十分に近似できる適切な複雑性を持ったモデルを使うことで、最良の汎化性能が実現されます。
そのために用いられるニューロン数選択アルゴリズムは、パーセプトロン中のニューロンの数の最適化を担います。
ここでは、グローイングニューロンというニューロン数選択アルゴリズムの一種を採用します。
次の図は、この過程の結果を表しています。青線は訓練誤差を、オレンジ線は検証誤差を表しています。
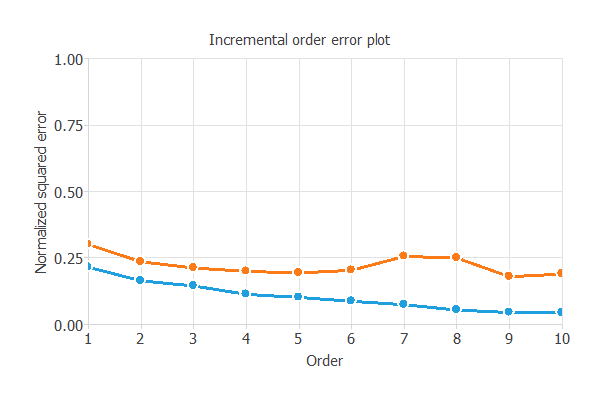 この手法では、少ないニューロンから始めて、検証過程を反復するごとにニューロンの数を増やしていきます。
そして、検証誤差が最小となるニューロンの数(この例では9個)を選択します。
それ以上の数のニューロンでは、過学習によって検証誤差は増大していきます。
この例では、ニューロン数選択アルゴリズムを経て0.211839NSEという検証誤差を達成しました。
この手法では、少ないニューロンから始めて、検証過程を反復するごとにニューロンの数を増やしていきます。
そして、検証誤差が最小となるニューロンの数(この例では9個)を選択します。
それ以上の数のニューロンでは、過学習によって検証誤差は増大していきます。
この例では、ニューロン数選択アルゴリズムを経て0.211839NSEという検証誤差を達成しました。
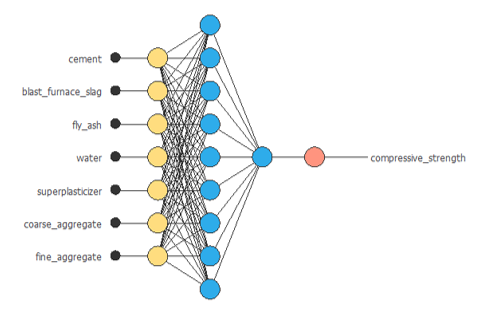
下の図が最終的なネットワーク構造です。
 テスト分析
テスト分析
近似モデルでの標準的な予測性能のテスト方法は、ニューラルネットワークの出力値と、これまでに使っていないデータ中のターゲットの値とを比較することです。
次の図は圧縮強度の予測値と実際の値との比較を図示したものです。
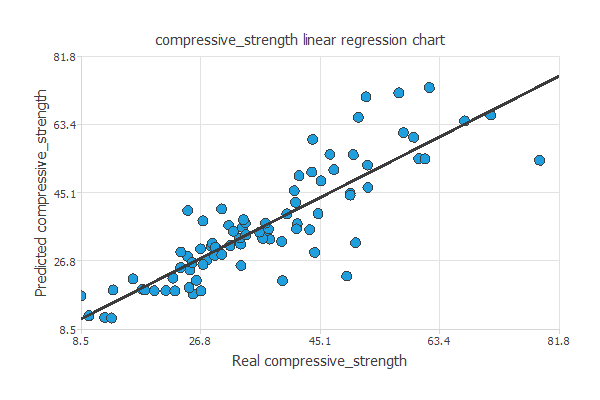 見ての通り、全領域にわたって双方の値はよく似通っています。
相関係数R2は0.861で、モデルが確かな予測性能を持っていることを示しています。
見ての通り、全領域にわたって双方の値はよく似通っています。
相関係数R2は0.861で、モデルが確かな予測性能を持っていることを示しています。
1つのテスト用インスタンスについての誤差を精査することも有益です。 この例では、可能な限りの性能を達成するため、いくつかの外れ値を除外しています。 誤差の平均は5.53%、標準偏差は3.69%で、この種の近似モデルにおいて良い値だと言えます。
 モデルの利用
モデルの利用
ニューラルネットワークが十分な精度で圧縮強度を予測できると分かれば、求める性能を持ったコンクリートを設計するためにモデルを利用する段階に進めます。
他の全ての入力値を固定した場合に、1つの入力値の関数として出力値がどのように変動するかを見ておくことは有益です。 Directional outputは、ある基準点を通る出力値の変化をプロットします。 例として、以下の入力値の組を基準点とします。
- セメント含有量: 265[kg/m^3]
- 高炉スラグ含有量: 86[kg/m^3]
- フライアッシュ含有量: 62[kg/m^3]
- 水含有量: 183[kg/m^3]
- 高性能減水剤含有量: 7[kg/m^3]
- 粗骨材含有量: 956[kg/m^3]
- 細骨材含有量: 764[kg/m^3]
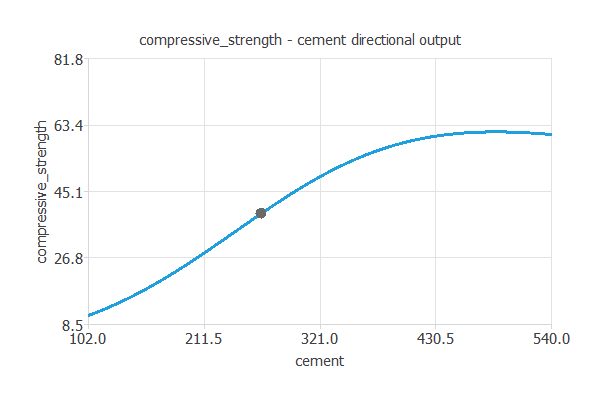 セメント含有量が増えると強度が高まることが分かります。
セメント含有量が増えると強度が高まることが分かります。