活用例
 複合火力発電所の性能向上
複合火力発電所の性能向上

複合火力発電所(コンバインドサイクル発電所)は、ガスタービン、蒸気タービン、排熱回収型蒸気発生器で構成されています。 このタイプの発電所では、ガスタービンと蒸気タービンを組み合わせた1つのユニットで発電し、1つのユニットから別のユニットへと電気を送ります。 排気真空度は蒸気タービンに影響を与え、環境変数はガスタービンの性能に影響を与えます。
この例では、生成されたエネルギー(電力)を排気真空度と環境変数の関数としてモデル化し、そのモデルを使用してプラントの性能を向上させることを目的としています。
リンク:
 アプリケーションの選択
アプリケーションの選択
予測すべき変数がエネルギー生産量であり連続的な値をとるため、この例では近似モデルを構築します。
ここでの主な目的は、環境変数と装置の制御変数の関数としてエネルギー生産量をモデル化することです。
 データセットの設定
データセットの設定
データセットは次の3つのコンセプトからなります。
- データソース
- 変数
- インスタンス
データセットには、コンバインドサイクル発電所が6年間にわたって収集した、5つの変数を持つ9568個のインスタンスが含まれています。 なお、データの取得は1秒ごとに行われています。 変数は以下の通りです。
入力
- 温度[℃]
- 排気真空度[cmHg]
- 周囲の圧力[mb]
- 相対湿度[%]
ターゲット
- 1時間あたりの発電量[MW]
このデータセットを、訓練用、検証用、テスト用のサブセットに、それぞれ60%、20%、20%のインスタンスを含むようランダムに分割します。 具体的には、訓練用に753個、検証用に375個、テスト用に375個のインスタンスを使用しています。
次にデータの分布を計算することで、データの正しさを確認したり、異常を検出したりできます。
下の図は、発電量のヒストグラムです。
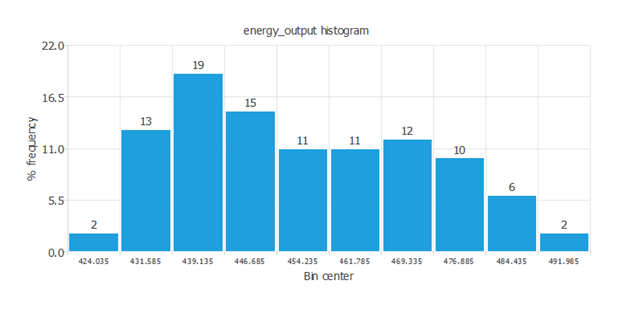 発電量が小さい場合が、大きい場合よりも多いことが見て取れます。
発電量が小さい場合が、大きい場合よりも多いことが見て取れます。
1つの入力と1つのターゲットの間の依存関係を調べることも重要です。
そのために、各入力とターゲットである発電量との相関図をプロットします。
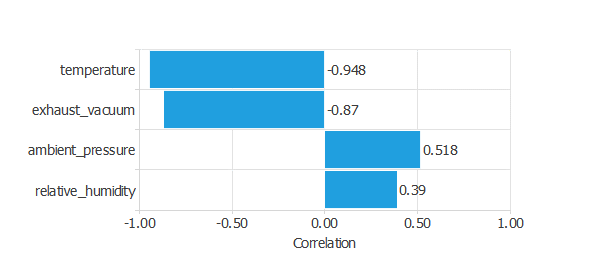 最も発電量との相関が強いのは"temperture: 温度"です(一般的に、温度が高いほど発電量は少なくなります)。
最も発電量との相関が強いのは"temperture: 温度"です(一般的に、温度が高いほど発電量は少なくなります)。
次に例として、発電量と排気真空度の散布図を作成してみます。
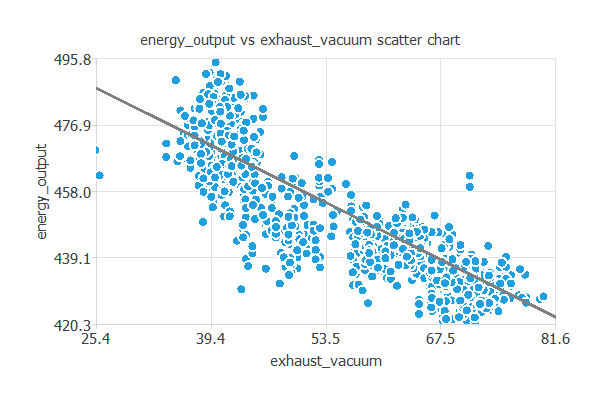 上図の通り、発電量は排気真空度と高い相関関係があります。
一般的に、排気真空度が高いほど発電量は少なくなります。
上図の通り、発電量は排気真空度と高い相関関係があります。
一般的に、排気真空度が高いほど発電量は少なくなります。
 ネットワーク構造の設定
ネットワーク構造の設定
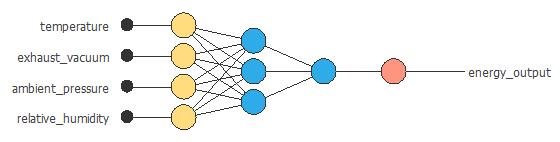
次のステップでは、近似関数を表現するニューラルネットワークを構築します。 近似モデルでは、ニューラルネットワークは次のように構成されます。
- スケーリング層
- パーセプトロン層
- アンスケーリング層
スケーリング層
スケーリング層には、入力の統計情報が含まれています。 すべての入力が正規分布を持つので、平均と標準偏差のスケーリング方法を使用します。
パーセプトロン層
ここでは2つのパーセプトロン層を使用しています。 1層目は、4つの入力、3つのニューロン、活性化関数として双曲線正接関数を持ちます。 1層目は3つの入力、1つのニューロン、活性化関数として線形関数を持ちます。
アンスケーリング層
アンスケーリング層は、ターゲットの統計情報を含みます。 ターゲットは正規分布なので、平均と標準偏差のアンスケーリング法を使用します。
次の図は、この例のニューラルネットワークを表しています。
 学習手法の設定
学習手法の設定
次のステップは、適切な学習手法の設定です。 一般的な学習手法は、以下の2つからなります。
- 損失関数
- 最適化アルゴリズム
損失関数
損失指数は、ニューラルネットワークが学習する量を定義し、誤差項と正則化項で構成されています。
誤差項としては、正規化二乗誤差を選択しました。 これは、ニューラルネットワークからの出力値とデータセット内のターゲットの値との間の二乗誤差を、その正規化係数で割ったものです。 正規化二乗誤差の値が1であれば、ニューラルネットワークはデータを"平均的に"予測していることを意味し、0であればデータを完全に予測していることを意味します。 この誤差項には、設定するパラメータはありません。
正則化項は、L2正則化です。 これは、パラメータの値を減らすことで、ニューラルネットワークの複雑さを制御するために用いられます。 この正則化項には弱い重みを使用しています。
最適化アルゴリズム
最適化アルゴリズムは、損失指数を最小化するようなニューラルネットワークのパラメータの探索を担います。 ここでは、準ニュートン法を最適化アルゴリズムとして採用しました。
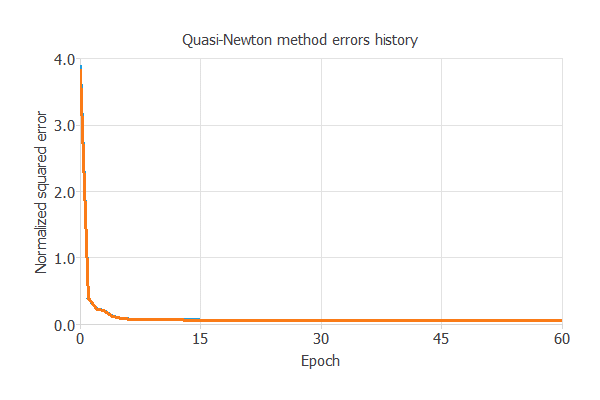
下の図は、学習過程において学習誤差(青)と検証誤差(オレンジ)が、エポック数(学習の繰り返し回数)に応じて減少する様子を示しています。
最終的な値は、訓練誤差=0.057NSE、検証誤差=0.067NSEとなりました。
 モデル選択
モデル選択
モデル選択は、ニューラルネットワークの汎化性能を改善するためにおこないます。
この例では、上で達成した検証誤差が十分小さい(0.067NSE)のでモデル選択は必要ありません。
 テスト分析
テスト分析
テスト分析の目的は、ニューラルネットワークの汎化能力を検証することです。 そのために、ここまでに使用していないテスト用のインスタンスを用います。
近似モデルを構築する際の標準的なテスト方法は、予測された出力値と実際の値との間で線形回帰分析を行うことです。
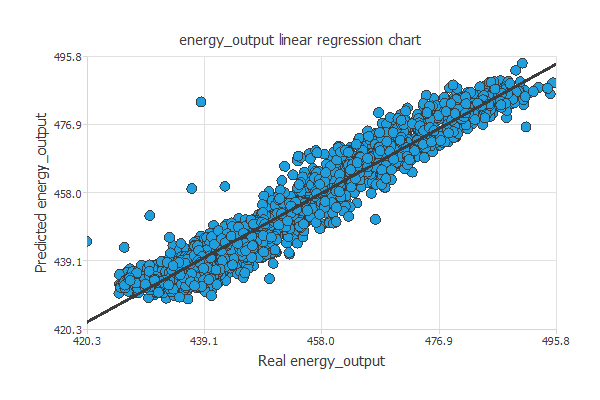 完全に結果が一致する場合、相関係数R2は1となります。
今回のケースではR2=0.968なので、ニューラルネットワークはテストデータを非常によく近似出来ていると言えます。
完全に結果が一致する場合、相関係数R2は1となります。
今回のケースではR2=0.968なので、ニューラルネットワークはテストデータを非常によく近似出来ていると言えます。
 モデルの利用
モデルの利用
ここまでに訓練されたニューラルネットワークは、見たことのない入力値に対して結果を予測するために使用されます。 例えば、以下のように与えられた入力値の組に対する出力値を算出できます。
入力値
- 温度: 19[℃]
- 排気真空度: 54[cmHg]
- 周囲の圧力: 1303[mb]
- 相対湿度: 73[%]
出力値
- 1時間あたりの発電量: 452[MW]
また、Directional outputを用いて、ある基準点を通る出力値をプロットできます。
例えば、上の4つの入力値を基準点とします。
そして、基準点から排気真空度のみを変えた場合の発電量をプロットしたものが以下の図です。
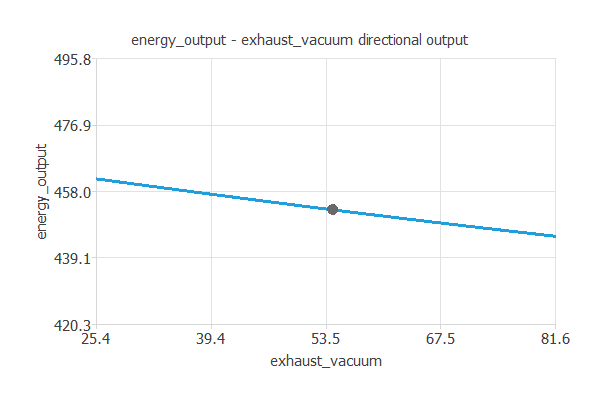 排気真空度を抑えることで発電量を増加させられることが分かります。
排気真空度を抑えることで発電量を増加させられることが分かります。