活用例
 自動車のCO2排出量の予測
自動車のCO2排出量の予測

近年の大きな課題である気候変動対策のために、大気中のCO2排出量を削減することが非常に重要です。 実際、多くの法律ではCO2排出量が一定量以上の車は禁止されており、基準を超えれば道路を走ることができません。
この問題に取り組むために、世界中のあらゆる場所に存在し得る、様々なタイプの車の大規模なデータセットを集めました。 ここでは、特定の独立変数を用いてCO2排出量を予測します。 エンジンの大きさやエンジンの特徴といったいくつかのパラメータを変更するだけで、この値を調整できます。
リンク:
 アプリケーションの選択
アプリケーションの選択
予測すべき変数(CO2排出量)が連続的なため、近似モデルです。
ここでの基本的な目標は、CO2排出量を自動車エンジンのいくつかの特性値の関数としてモデル化することです。
 データセットの設定
データセットの設定
最初のステップは、近似モデルの情報源であるデータセットの準備です。 データセットは以下で構成されています。
- データソース
- 変数
- インスタンス
この例では、変数(列)の数は12で、インスタンス(行)の数は7385です。 次の12個の変数があります。
入力
- 車体のタイプ
- エンジンの大きさ[L]
- シリンダーの数
- トランスミッション(Automatic, Automated manual, Automatic with select shift, Continuously variable, Manual)
- 燃料の種類(レギュラー, ハイオク, 軽油, エタノールE85, 天然ガス)
ターゲット
- CO2排出量(市街地と高速道路を組み合わせた走行時)[g/km]
未使用
- 調査対象のカーブランド
- 車のモデル名
- 市街地での燃費[L/100km]
- 高速道路の燃費[L/100km]
- 複合燃費(市街地55%, 高速道路45%)[L/100km]
- 複合燃費(市街地55%, 高速道路45%)[m/gal]
また、"車体のタイプ"には多くのカテゴリー変数が含まれているため分析するには少し問題があることがわかりました。 しかし、さらに調べてみると、この変数を含む場合よりも含まない場合の方が最終的な検証誤差が高いことがわかりました。 ニューラルネットワークの主な目的の1つは、検証誤差をできるだけ少なくすることなので、"車体のタイプ"も入力として扱います。
他にも"未使用"にしておくべき変数があります。それは、"燃費(市街地、高速道路、複合全て)"の変数です。 これらの入力は研究の対象になり得ますが(CO2と燃費は互いに依存しています)、最終的な出力としてCO2排出量を見た方が視覚的に分かりやすいでしょう。
このデータセットをランダムに分割し、それぞれ60%、20%、20%のインスタンスを含む訓練用、検証用、テスト用のサブセットとします。 具体的には、訓練用に4431個、検証用に1477個、テスト用に1477個のインスタンスを使用しました。
すべてのデータセット情報が設定されたら、データの品質を確認するためにいくつかの分析を行います。
例えば、データの分布を計算することができます。
次の図は、対象となる変数(CO2排出量)のヒストグラムを示しています。
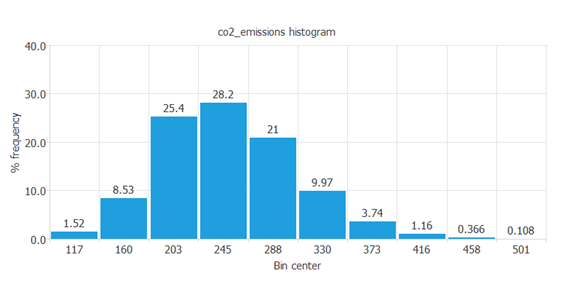 この図を見ると、CO2排出量は正規分布に従っていることがわかります。
実際、CO2排出量の中央値が先ほどの制限値を下回っている車がたくさんあります。
一方で今回の調査では、CO2排出量が非常に多く現在では運転できないような車が全体の0.108%存在していることがわかります。
この図を見ると、CO2排出量は正規分布に従っていることがわかります。
実際、CO2排出量の中央値が先ほどの制限値を下回っている車がたくさんあります。
一方で今回の調査では、CO2排出量が非常に多く現在では運転できないような車が全体の0.108%存在していることがわかります。
次の図のように、入力とターゲットの相関関係を表すこともできます。
これにより、様々な入力がCO2排出量に与える影響を確認することができます。
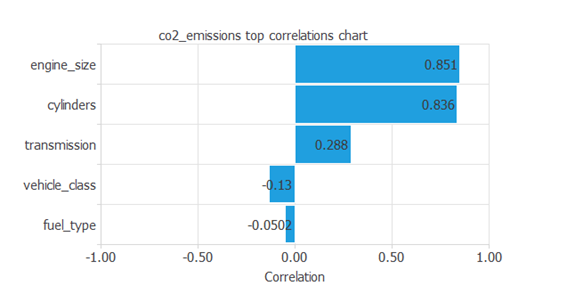 上のグラフは、いくつかの入力がCO2排出量に重要な依存性を持っていることを示しています。
例えば、"engine_size: エンジンの大きさ"と"cylinders: シリンダーの数"は、CO2排出量と正の相関があります。
一方で、排出量と負の相関を持つ入力もあります。
上のグラフは、いくつかの入力がCO2排出量に重要な依存性を持っていることを示しています。
例えば、"engine_size: エンジンの大きさ"と"cylinders: シリンダーの数"は、CO2排出量と正の相関があります。
一方で、排出量と負の相関を持つ入力もあります。
また例えば、CO2排出量とエンジンの大きさを比較した散布図を作成することもできます。
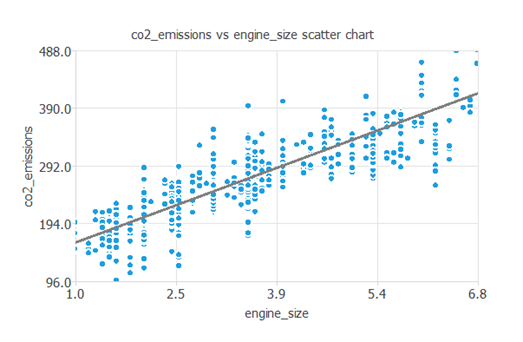 一般的に、エンジンが大きくなればなるほど排出量も多くなります。
ただし、CO2排出量はすべての入力に同時に依存します。
一般的に、エンジンが大きくなればなるほど排出量も多くなります。
ただし、CO2排出量はすべての入力に同時に依存します。
 ネットワーク構造の設定
ネットワーク構造の設定
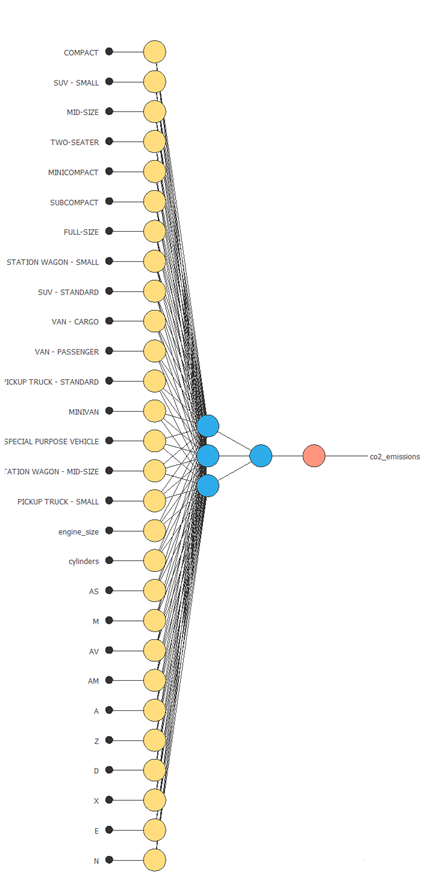
ニューラルネットワークは、燃費、トランスミッション、その他の車のエンジン特性の関数としてCO2排出量を出力します。 近似モデルでは、ニューラルネットワークは次のように構成されています。
- スケーリング層
- パーセプトロン層
- アンスケーリング層
スケーリング層
スケーリング層は、元の入力値を正規化された値に変換します。 ここでは、入力値の平均値が0、標準偏差が1になるように、平均値と標準偏差のスケーリング方法が設定されています。
パーセプトロン層
ここでは、2つのパーセプトロン層がニューラルネットワークに挿入されています。 ほとんどの事例では、この層の数で十分です。 第1層は28個の入力と3つのニューロンを持ち、第2層は3つの入力と1つのニューロンを持ちます。
アンスケーリング層
アンスケーリング層は、ニューラルネットワークから得られる正規化された値をターゲットに合わせて変換します。 ここでは、平均値と標準偏差のアンスケーリング手法を使用します。
図は、以上の結果として得られたネットワーク構造を示しています。
 学習手法の設定
学習手法の設定
次のステップでは、ニューラルネットワークが何を学習するかを規定する、学習手法を選択します。 一般的な学習手法は、2つのコンセプトで構成されています。
- 損失関数
- 最適化アルゴリズム
損失関数
損失関数として、L2正則化による正規化二乗誤差を選択しました。 この損失関数は、近似モデルのデフォルトです。
最適化アルゴリズム
最適化アルゴリズムには、準ニュートン法を採用しました。 この最適化アルゴリズムは、今回のような中規模のアプリケーションではデフォルトとなっています。
学習手法の設定が完了したら、ニューラルネットワークに学習をさせます。
次の図は、学習過程において、学習エポック(繰り返し回数)に応じて訓練誤差(青)と検証誤差(オレンジ)が減少する様子を示しています。
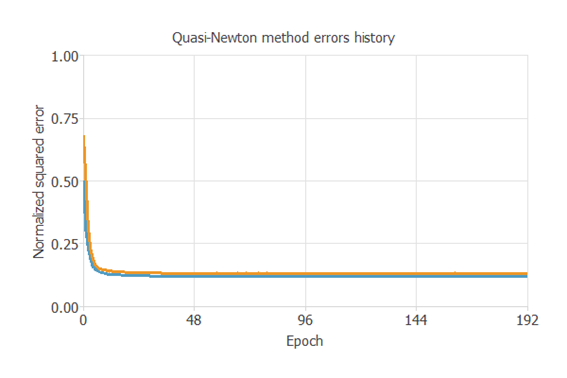 学習の結果で最も重要なのは、最終的な検証誤差です。
これは、ニューラルネットワークの汎化能力の指標となります。
ここでは、最終的な検証誤差は0.145NSEです。
学習の結果で最も重要なのは、最終的な検証誤差です。
これは、ニューラルネットワークの汎化能力の指標となります。
ここでは、最終的な検証誤差は0.145NSEです。
 モデル選択
モデル選択
モデル選択の目的は、最も優れた汎化性能を持つネットワーク構造を見つけることです。 つまり、先ほど得られた最終的な検証誤差(0.145NSE)を改善することを目的とします。
最小の検証誤差は、入力とターゲットの関係性を表現するのに最適な複雑さを持つモデルを使用することで達成されます。 そのために用いるニューロン数選択アルゴリズムでは、ニューロン数を変えながら学習を繰り返し、最適なニューロン数を見つける役割を担います。 このアルゴリズムでは、最終的な検証誤差は、ある時点で最小値をとります。 この例では、最適なニューロンの数は10で、その時の検証誤差は0.131NSEになります。
 テスト分析
テスト分析
テスト分析の目的は、学習したニューラルネットワークの汎化性能を検証することです。 そのために、ニューラルネットワークの予測値を実測値と比較します。
近似モデルの標準的なテスト手法としては、テスト用データセットを用いた、予測値と実測値の間の線形回帰分析があります。
次の図は、このテスト分析によって得られた結果を示しています。
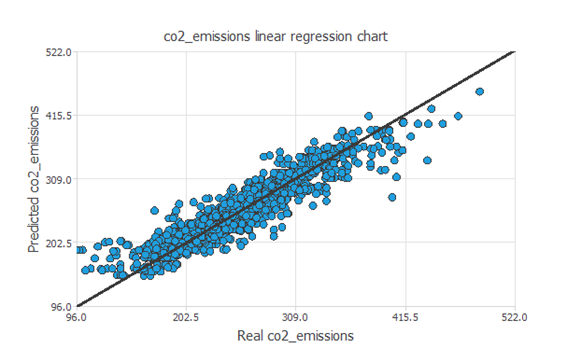 上のグラフから、ニューラルネットワークがCO2排出量データの全範囲をうまく予測していることがわかります。
また、相関値はR2=0.924で、1に非常に近い値を示しています。
上のグラフから、ニューラルネットワークがCO2排出量データの全範囲をうまく予測していることがわかります。
また、相関値はR2=0.924で、1に非常に近い値を示しています。
 モデルの利用
モデルの利用
このモデルは、学習時と同じデータ範囲において、ある自動車のCO2排出量を満足のいく品質で推定できるようになりました。
Directional outputをプロットすることで、他のすべての入力値を固定した場合の、1つの入力値の変化によるCO2排出量の変化を見ることができます。
次のプロットは、他の入力値を次の値で固定した時の、シリンダー数の関数としてのCO2排出量を示しています。
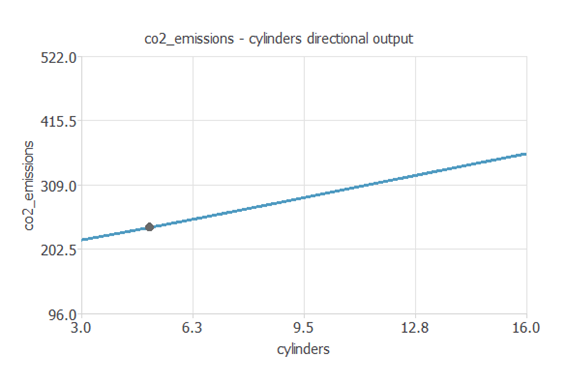 他の入力値は次の値で固定しています。
他の入力値は次の値で固定しています。
- 車体のタイプ: COMPACT
- エンジンの大きさ: 3.16[L]
- シリンダーの数: 5
- トランスミッション: Automatic with select shift
- 燃料の種類: ハイオク